接入 Marker PDF 文档解析
使用 Marker 解析 PDF 文档,可实现图片提取和布局识别
背景
PDF 是一个相对复杂的文件格式,在 FastGPT 内置的 pdf 解析器中,依赖的是 pdfjs 库解析,该库基于逻辑解析,无法有效的理解复杂的 pdf 文件。所以我们在解析 pdf 时候,如果遇到图片、表格、公式等非简单文本内容,会发现解析效果不佳。
市面上目前有多种解析 PDF 的方法,比如使用 Marker,该项目使用了 Surya 模型,基于视觉解析,可以有效提取图片、表格、公式等复杂内容。
在 FastGPT v4.9.0 版本中,开源版用户可以在config.json文件中添加systemEnv.customPdfParse配置,来使用 Marker 解析 PDF 文件。商业版用户直接在 Admin 后台根据表单指引填写即可。需重新拉取 Marker 镜像,接口格式已变动。
使用教程
1. 安装 Marker
参考文档 Marker 安装教程,安装 Marker 模型。封装的 API 已经适配了 FastGPT 自定义解析服务。
这里介绍快速 Docker 安装的方法:
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
docker run --gpus all -itd -p 7231:7232 --name model_pdf_v2 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.2
2. 添加 FastGPT 文件配置
{
xxx
"systemEnv": {
xxx
"customPdfParse": {
"url": "http://xxxx.com/v2/parse/file", // 自定义 PDF 解析服务地址 marker v0.2
"key": "", // 自定义 PDF 解析服务密钥
"doc2xKey": "", // doc2x 服务密钥
"price": 0 // PDF 解析服务价格
}
}
}
需要重启服务。
3. 测试效果
通过知识库上传一个 pdf 文件,并勾选上 PDF 增强解析。
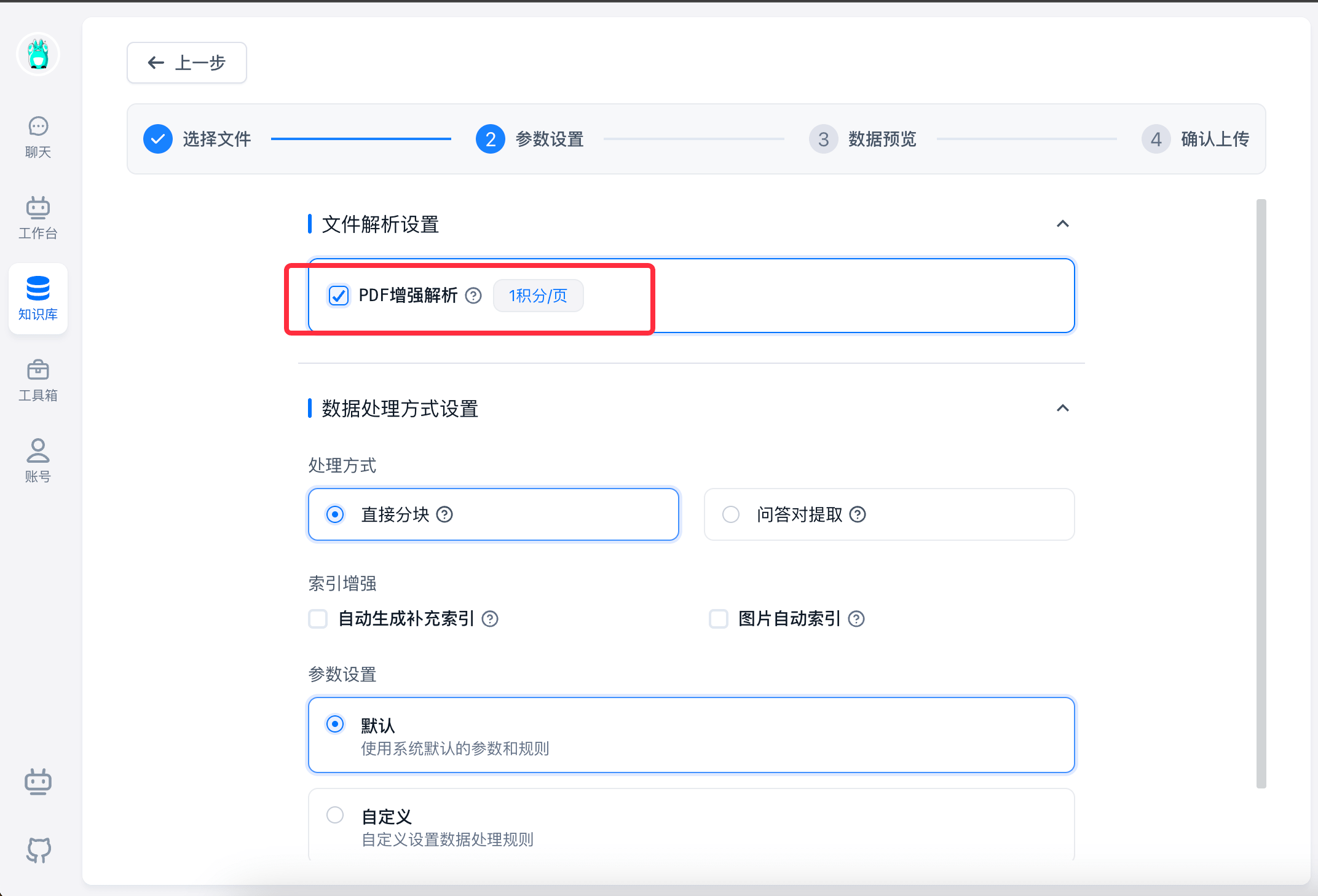
确认上传后,可以在日志中看到 LOG (LOG_LEVEL需要设置 info 或者 debug):
[Info] 2024-12-05 15:04:42 Parsing files from an external service
[Info] 2024-12-05 15:07:08 Custom file parsing is complete, time: 1316ms
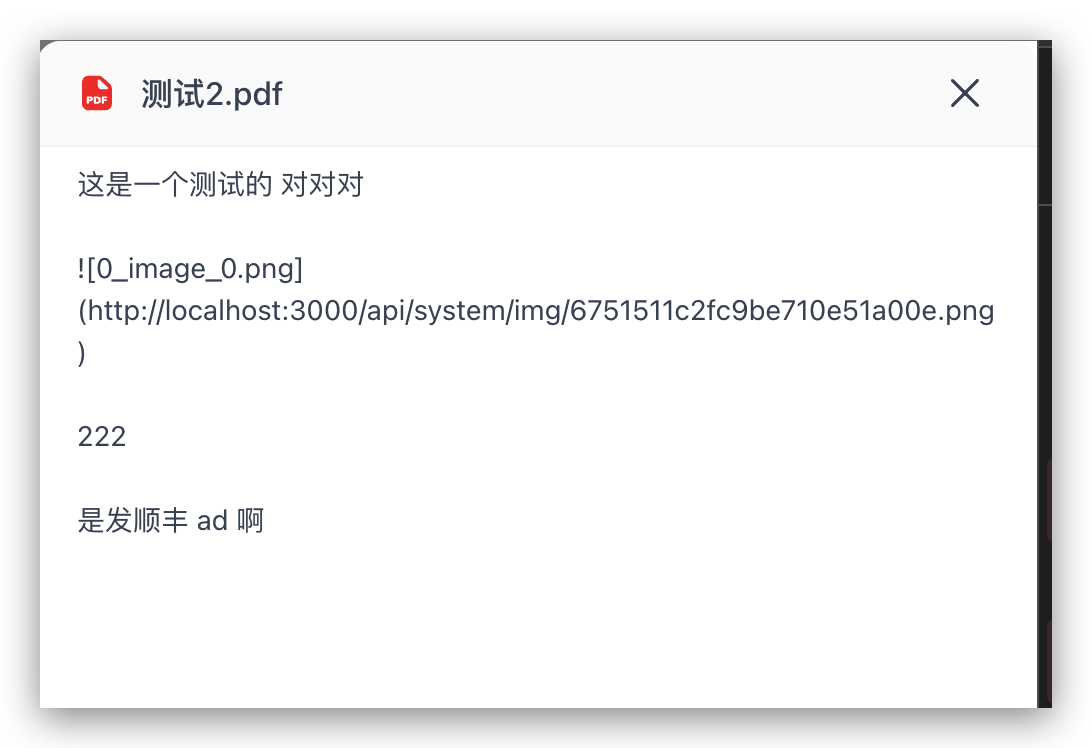
然后你就可以发现,通过 Marker 解析出来的 pdf 会携带图片链接:
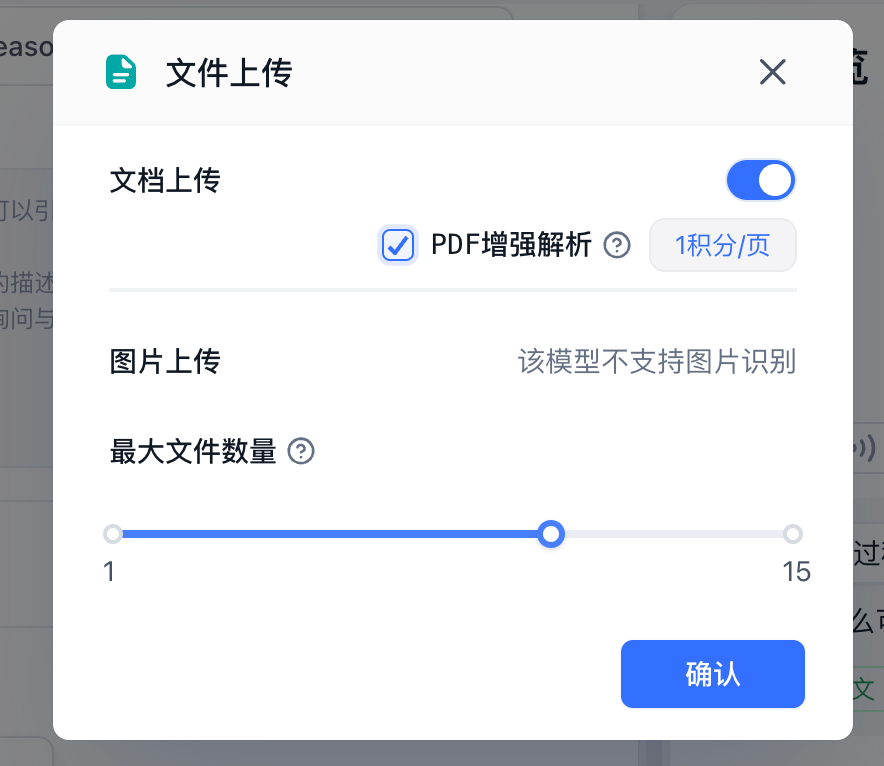
同样的,在应用中,你可以在文件上传配置里,勾选上 PDF 增强解析。
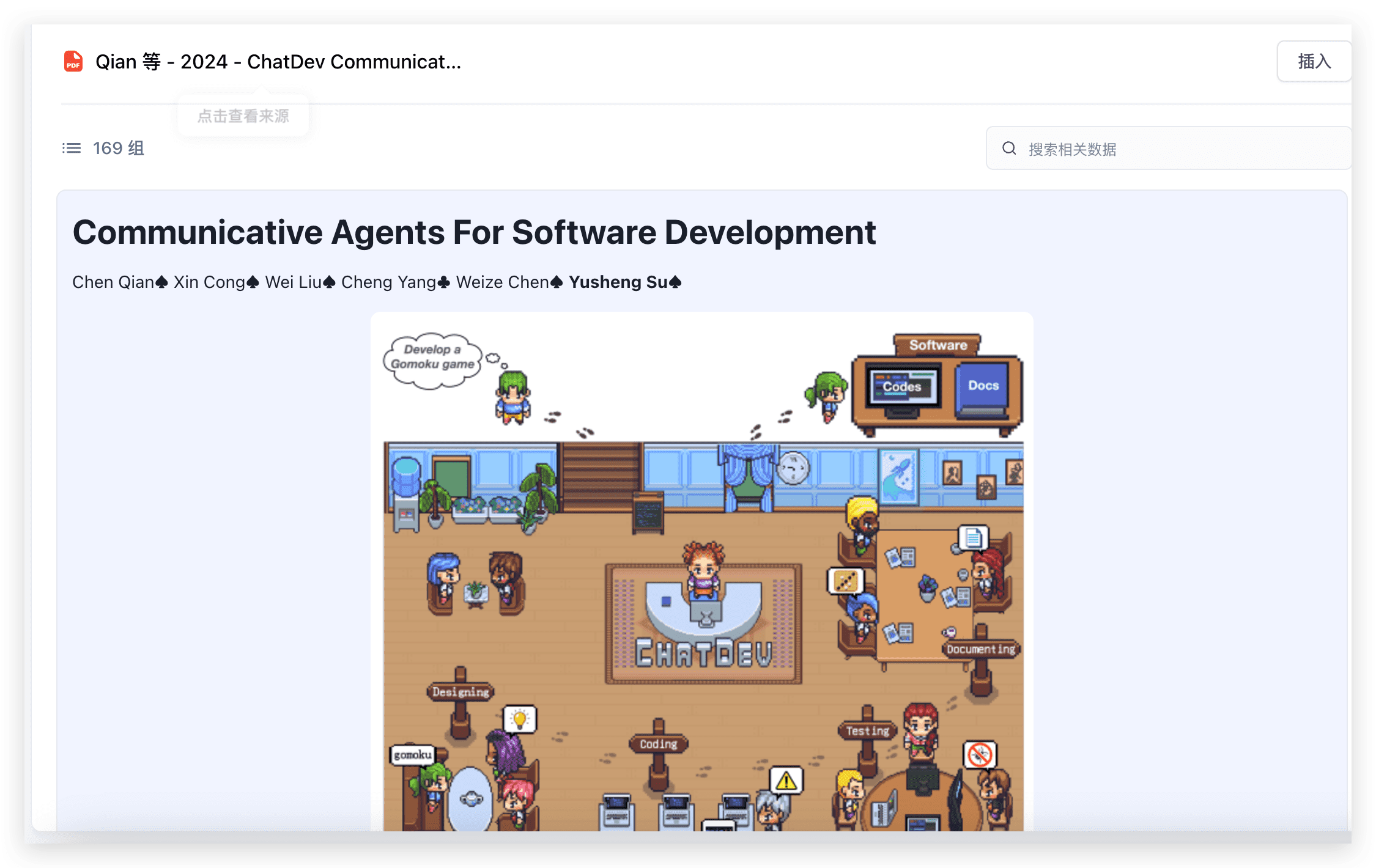
效果展示
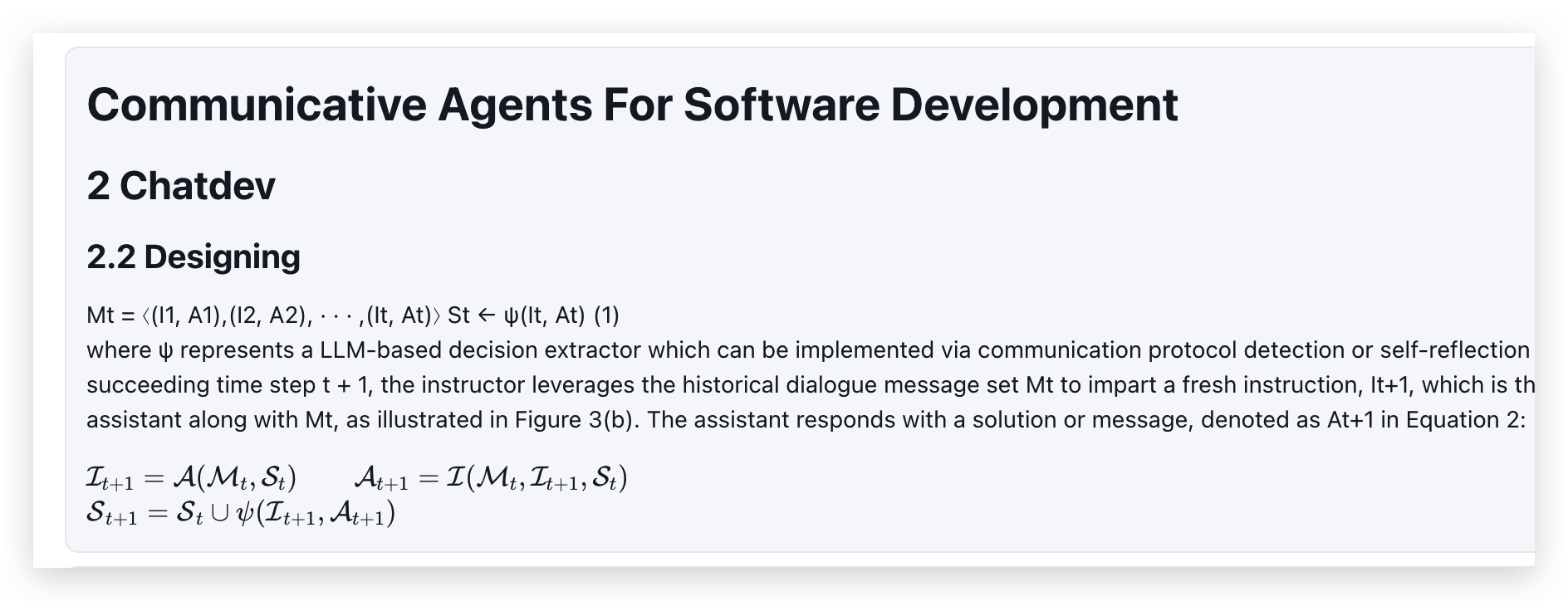
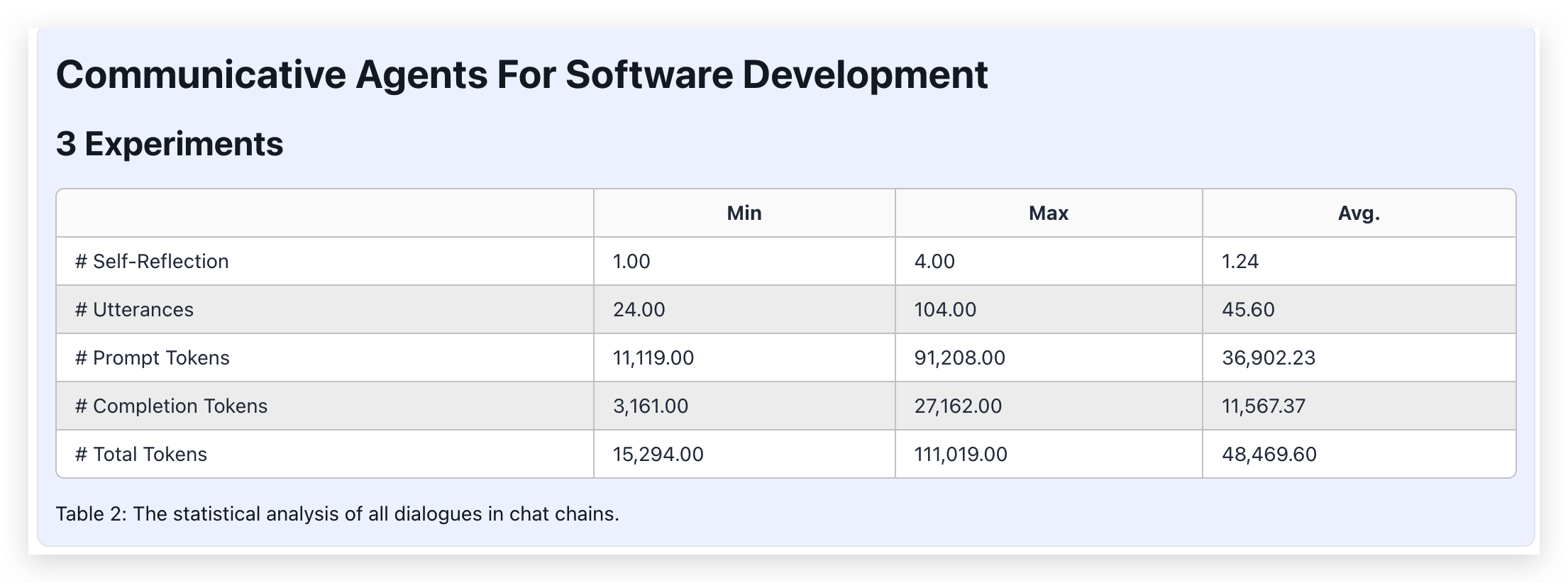
以清华的 ChatDev Communicative Agents for Software Develop.pdf 为例,展示 Marker 解析的效果:
 |  |  |
 |  |  |
上图是分块后的结果,下图是 pdf 原文。整体图片、公式、表格都可以提取出来,效果还是杠杠的。
不过要注意的是,Marker 的协议是GPL-3.0 license,请在遵守协议的前提下使用。
旧版 Marker 使用方法
FastGPT V4.9.0 版本之前,可以用以下方式,试用 Marker 解析服务。
安装和运行 Marker 服务:
docker pull crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
docker run --gpus all -itd -p 7231:7231 --name model_pdf_v1 -e PROCESSES_PER_GPU="2" crpi-h3snc261q1dosroc.cn-hangzhou.personal.cr.aliyuncs.com/marker11/marker_images:v0.1
并修改 FastGPT 环境变量:
CUSTOM_READ_FILE_URL=http://xxxx.com/v1/parse/file
CUSTOM_READ_FILE_EXTENSION=pdf
- CUSTOM_READ_FILE_URL - 自定义解析服务的地址, host改成解析服务的访问地址,path 不能变动。
- CUSTOM_READ_FILE_EXTENSION - 支持的文件后缀,多个文件类型,可用逗号隔开。