使用 Ollama 接入本地模型
采用 Ollama 部署自己的模型
Ollama 是一个开源的AI大模型部署工具,专注于简化大语言模型的部署和使用,支持一键下载和运行各种大模型。
安装 Ollama
Ollama 本身支持多种安装方式,但是推荐使用 Docker 拉取镜像部署。如果是个人设备上安装了 Ollama 后续需要解决如何让 Docker 中 FastGPT 容器访问宿主机 Ollama的问题,较为麻烦。
Docker 安装(推荐)
你可以使用 Ollama 官方的 Docker 镜像来一键安装和启动 Ollama 服务(确保你的机器上已经安装了 Docker),命令如下:
docker pull ollama/ollama
docker run --rm -d --name ollama -p 11434:11434 ollama/ollama
如果你的 FastGPT 是在 Docker 中进行部署的,建议在拉取 Ollama 镜像时保证和 FastGPT 镜像处于同一网络,否则可能出现 FastGPT 无法访问的问题,命令如下:
docker run --rm -d --name ollama --network (你的 Fastgpt 容器所在网络) -p 11434:11434 ollama/ollama
主机安装
如果你不想使用 Docker ,也可以采用主机安装,以下是主机安装的一些方式。
MacOS
如果你使用的是 macOS,且系统中已经安装了 Homebrew 包管理器,可通过以下命令来安装 Ollama:
brew install ollama
ollama serve #安装完成后,使用该命令启动服务
Linux
在 Linux 系统上,你可以借助包管理器来安装 Ollama。以 Ubuntu 为例,在终端执行以下命令:
curl https://ollama.com/install.sh | sh #此命令会从官方网站下载并执行安装脚本。
ollama serve #安装完成后,同样启动服务
Windows
在 Windows 系统中,你可以从 Ollama 官方网站 下载 Windows 版本的安装程序。下载完成后,运行安装程序,按照安装向导的提示完成安装。安装完成后,在命令提示符或 PowerShell 中启动服务:
ollama serve #安装完成并启动服务后,你可以在浏览器中访问 http://localhost:11434 来验证 Ollama 是否安装成功。
补充说明
如果你是采用的主机应用 Ollama 而不是镜像,需要确保你的 Ollama 可以监听0.0.0.0。
1. Linxu 系统
如果 Ollama 作为 systemd 服务运行,打开终端,编辑 Ollama 的 systemd 服务文件,使用命令sudo systemctl edit ollama.service,在[Service]部分添加Environment=“OLLAMA_HOST=0.0.0.0”。保存并退出编辑器,然后执行sudo systemctl daemon - reload和sudo systemctl restart ollama使配置生效。
2. MacOS 系统
打开终端,使用launchctl setenv ollama_host “0.0.0.0"命令设置环境变量,然后重启 Ollama 应用程序以使更改生效。
3. Windows 系统
通过 “开始” 菜单或搜索栏打开 “编辑系统环境变量”,在 “系统属性” 窗口中点击 “环境变量”,在 “系统变量” 部分点击 “新建”,创建一个名为OLLAMA_HOST的变量,变量值设置为0.0.0.0,点击 “确定” 保存更改,最后从 “开始” 菜单重启 Ollama 应用程序。
Ollama 拉取模型镜像
在安装 Ollama 后,本地是没有模型镜像的,需要自己去拉取 Ollama 中的模型镜像。命令如下:
# Docker 部署需要先进容器,命令为: docker exec -it < Ollama 容器名 > /bin/sh
ollama pull <模型名>
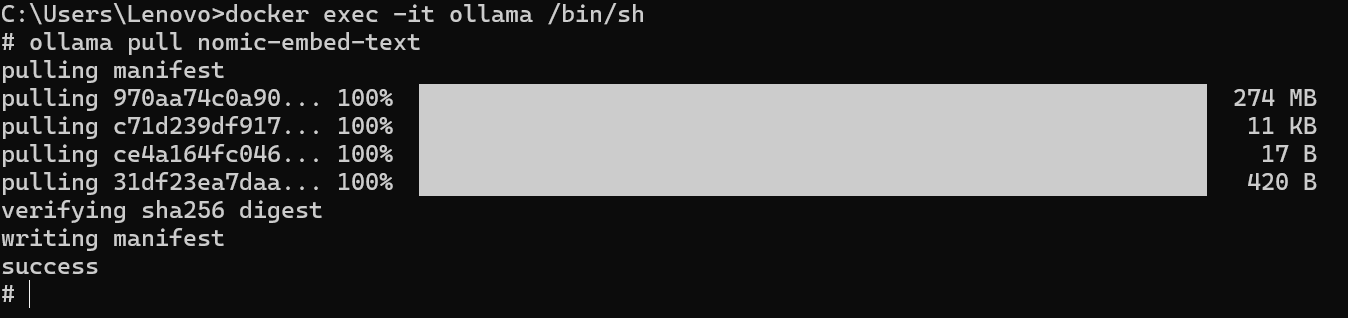
测试通信
在安装完成后,需要进行检测测试,首先进入 FastGPT 所在的容器,尝试访问自己的 Ollama ,命令如下:
docker exec -it < FastGPT 所在的容器名 > /bin/sh
curl http://XXX.XXX.XXX.XXX:11434 #容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
看到访问显示自己的 Ollama 服务以及启动,说明可以正常通信。
将 Ollama 接入 FastGPT
1. 查看 Ollama 所拥有的模型
首先采用下述命令查看 Ollama 中所拥有的模型,
# Docker 部署 Ollama,需要此命令 docker exec -it < Ollama 容器名 > /bin/sh
ollama ls

2. AI Proxy 接入
如果你采用的是 FastGPT 中的默认配置文件部署这里,即默认采用 AI Proxy 进行启动。

以及在确保你的 FastGPT 可以直接访问 Ollama 容器的情况下,无法访问,参考上文点此跳转的安装过程,检测是不是主机不能监测0.0.0.0,或者容器不在同一个网络。

在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。详细参考这里
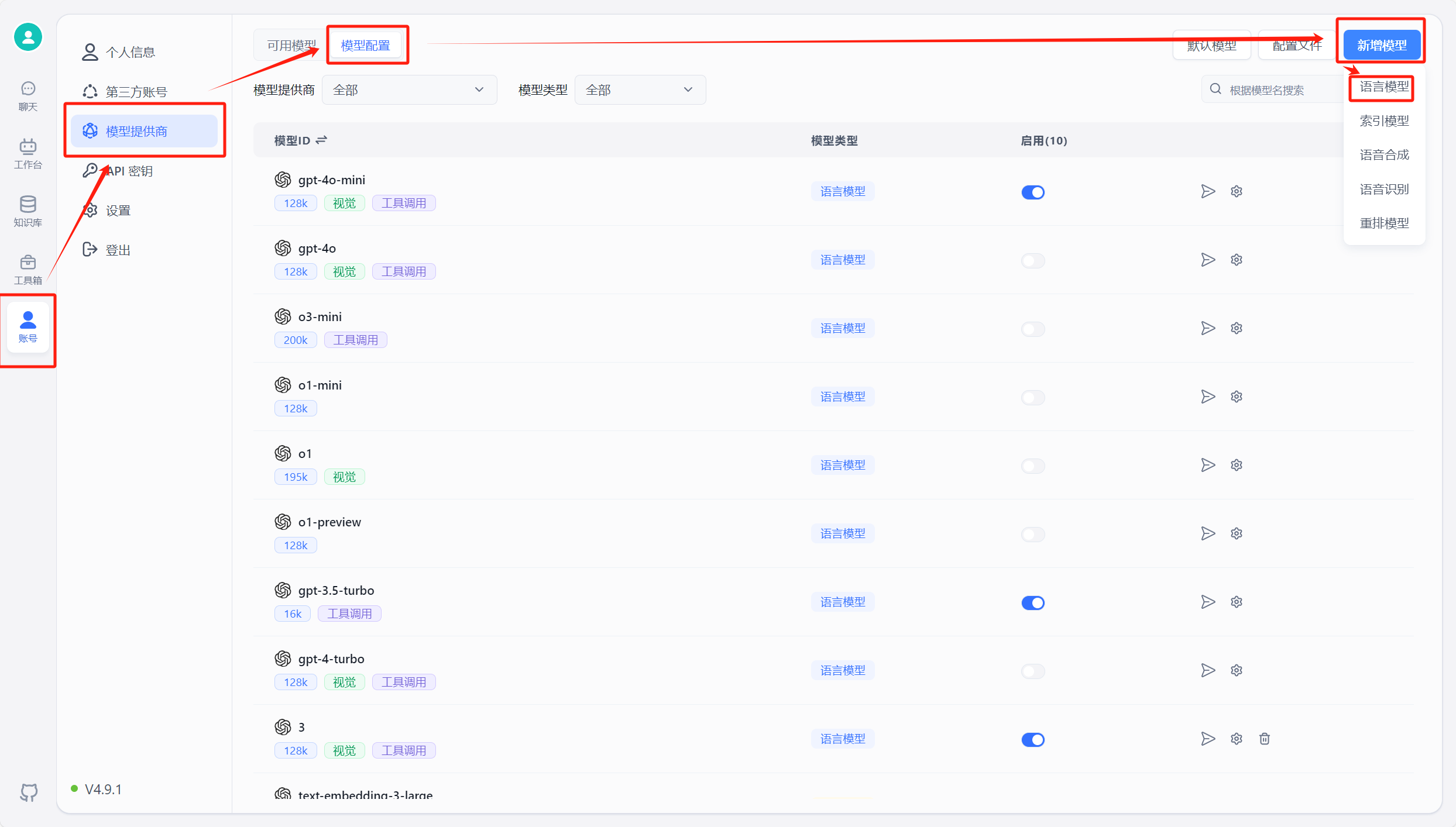
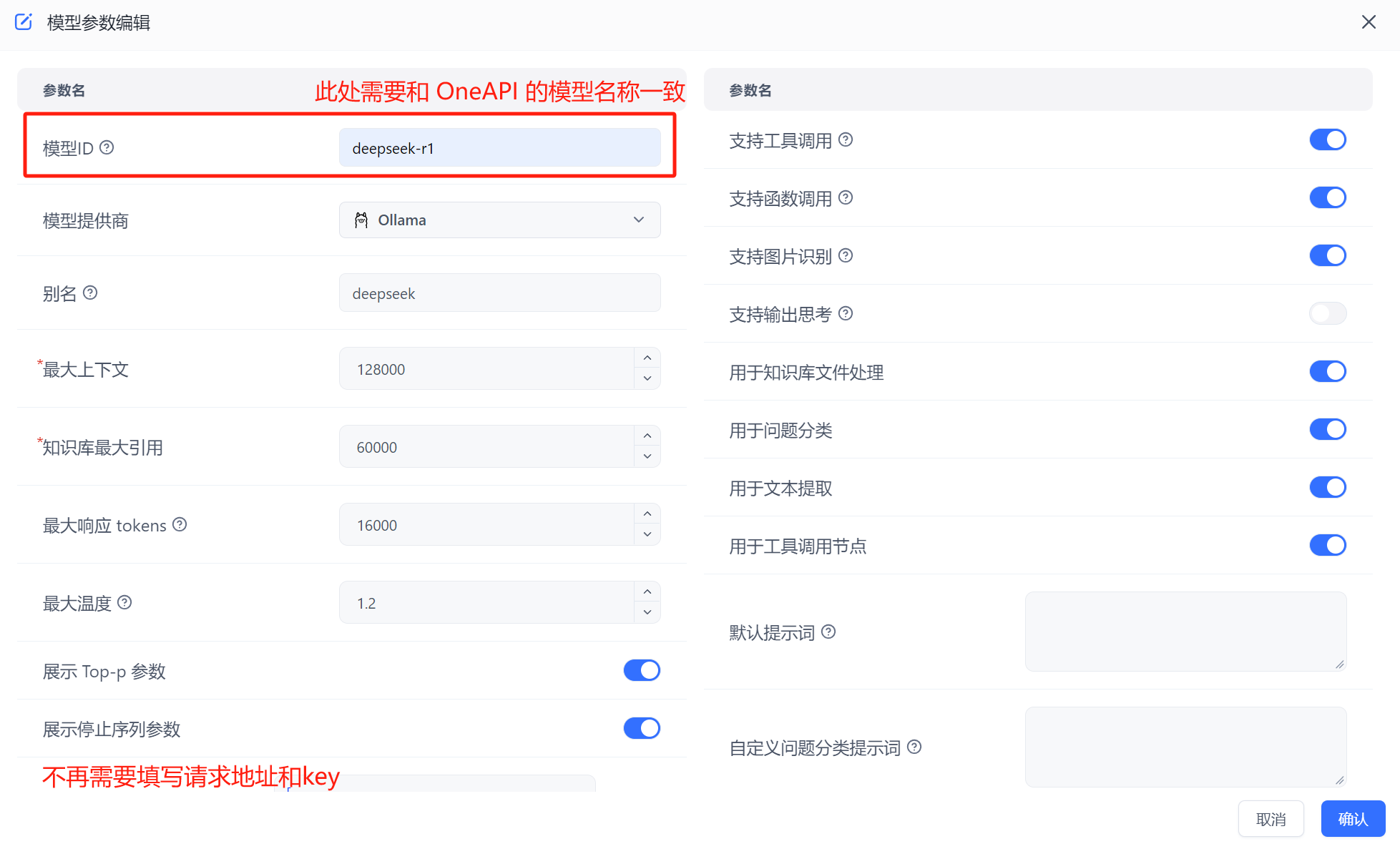
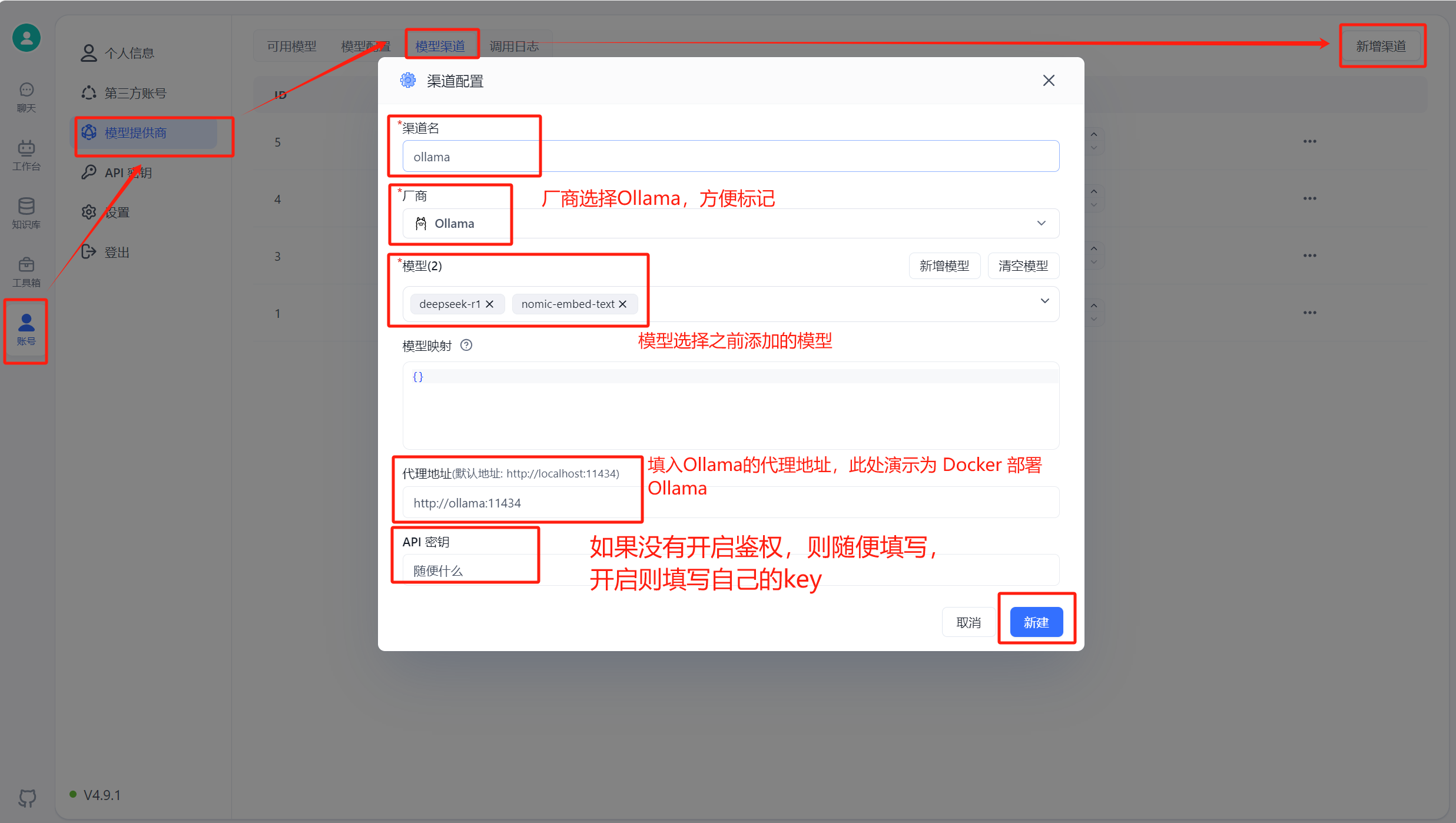
运行 FastGPT ,在页面中选择账号->模型提供商->模型渠道->新增渠道。之后,在渠道选择中选择 Ollama ,然后加入自己拉取的模型,填入代理地址,如果是容器中安装 Ollama ,代理地址为http://地址:端口,补充:容器部署地址为“http://<容器名>:<端口>”,主机安装地址为"http://<主机IP>:<端口>",主机IP不可为localhost
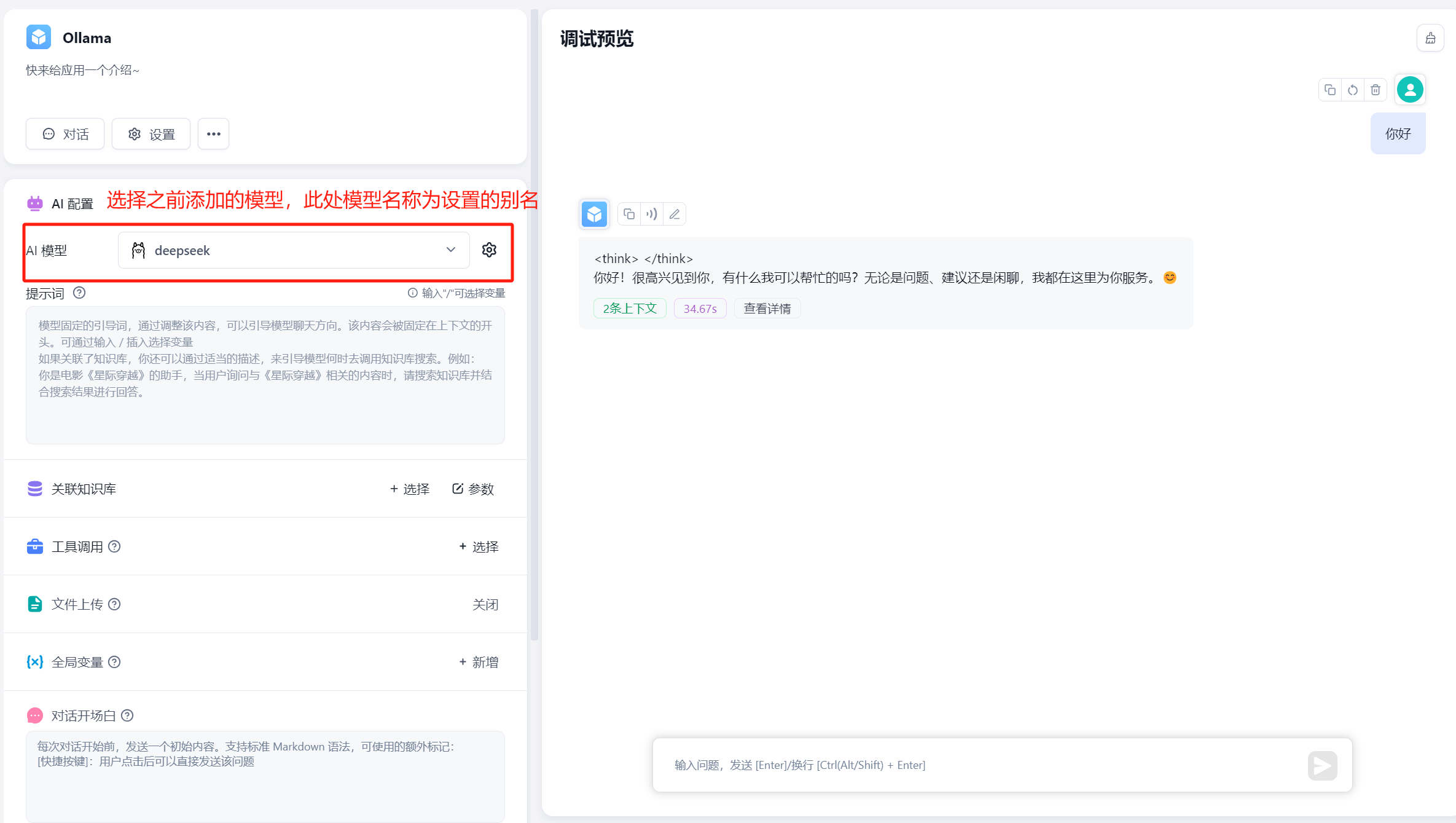
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
3. OneAPI 接入
如果你想使用 OneAPI ,首先需要拉取 OneAPI 镜像,然后将其在 FastGPT 容器的网络中运行。具体命令如下:
# 拉取 oneAPI 镜像
docker pull intel/oneapi-hpckit
# 运行容器并指定自定义网络和容器名
docker run -it --network < FastGPT 网络 > --name 容器名 intel/oneapi-hpckit /bin/bash
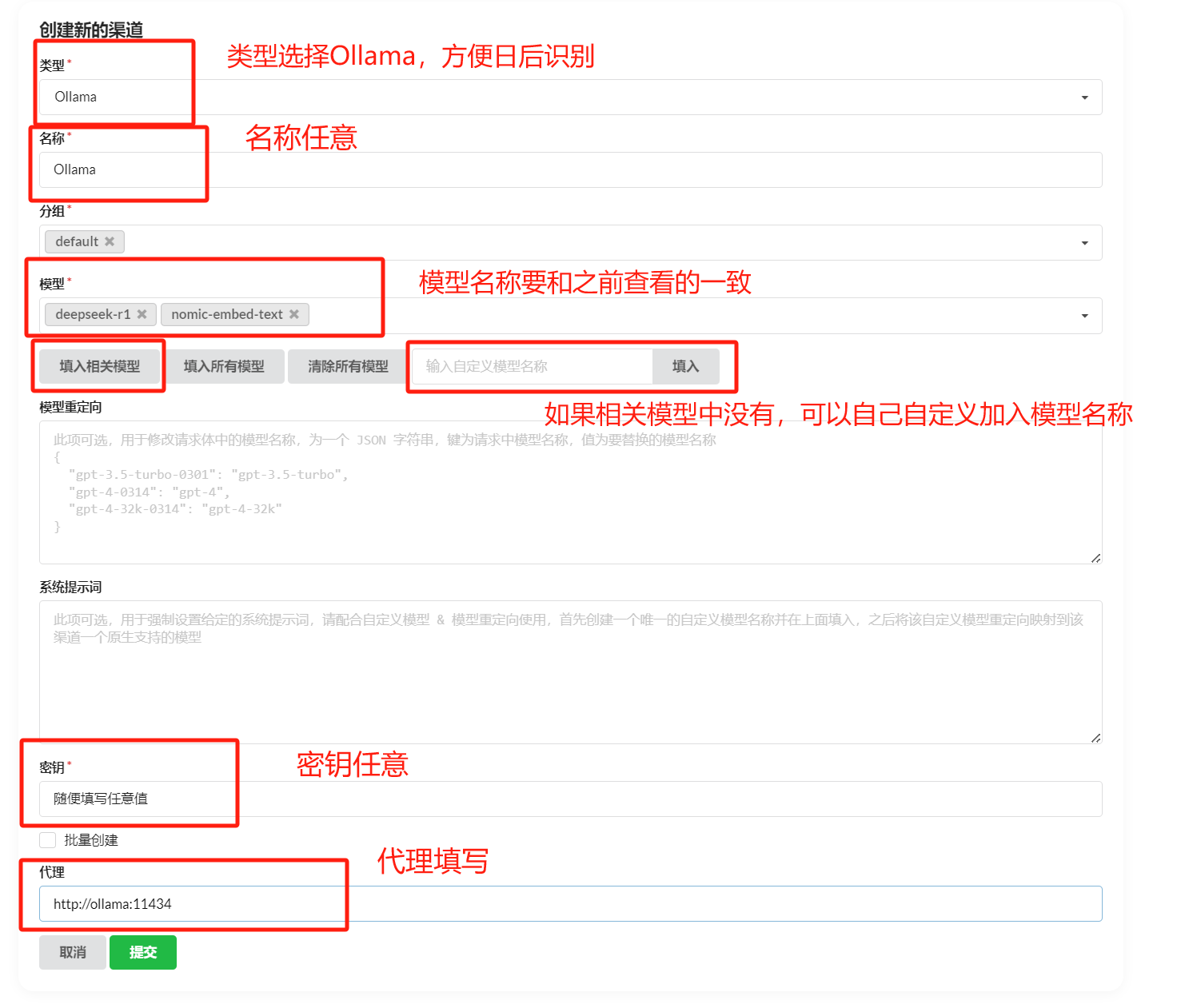
进入 OneAPI 页面,添加新的渠道,类型选择 Ollama ,在模型中填入自己 Ollama 中的模型,需要保证添加的模型名称和 Ollama 中一致,再在下方填入自己的 Ollama 代理地址,默认http://地址:端口,不需要填写/v1。添加成功后在 OneAPI 进行渠道测试,测试成功则说明添加成功。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>
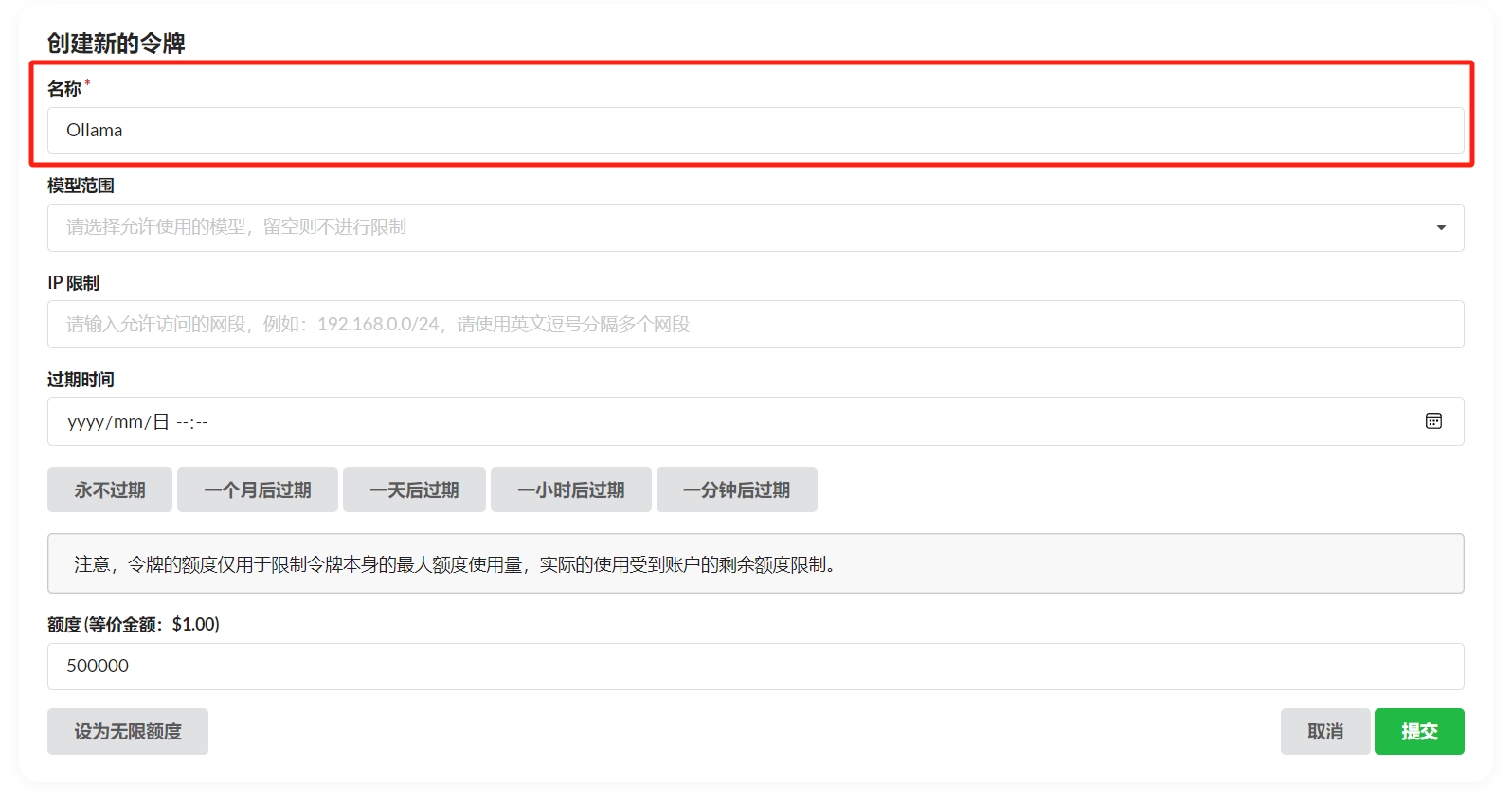
渠道添加成功后,点击令牌,点击添加令牌,填写名称,修改配置。
修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,在 OPENAI_BASE_URL 中加入自己的 OneAPI 开放地址,默认是http://地址:端口/v1,v1必须填写。KEY 中填写自己在 OneAPI 的令牌。

直接跳转5添加模型,并使用。
4. 直接接入
如果你既不想使用 AI Proxy,也不想使用 OneAPI,也可以选择直接接入,修改部署 FastGPT 的 docker-compose.yml 文件,在其中将 AI Proxy 的使用注释,采用和 OneAPI 的类似配置。注释掉 AIProxy 相关代码,在OPENAI_BASE_URL中加入自己的 Ollama 开放地址,默认是http://地址:端口/v1,强调:v1必须填写。在KEY中随便填入,因为 Ollama 默认没有鉴权,如果开启鉴权,请自行填写。其他操作和在 OneAPI 中加入 Ollama 一致,只需在 FastGPT 中加入自己的模型即可使用。此处演示采用的是 Docker 部署 Ollama 的效果,主机 Ollama需要修改代理地址为http://<主机IP>:<端口>

完成后点击这里进行模型添加并使用。
5. 模型添加和使用
在 FastGPT 中点击账号->模型提供商->模型配置->新增模型,添加自己的模型即可,添加模型时需要保证模型ID和 OneAPI 中的模型名称一致。
在工作台中创建一个应用,选择自己之前添加的模型,此处模型名称为自己当时设置的别名。注:同一个模型无法多次添加,系统会采取最新添加时设置的别名。
6. 补充
上述接入 Ollama 的代理地址中,主机安装 Ollama 的地址为“http://<主机IP>:<端口>”,容器部署 Ollama 地址为“http://<容器名>:<端口>”