私有部署常见问题
FastGPT 私有部署常见问题
一、错误排查方式
可以先找找Issue,或新提 Issue,私有部署错误,务必提供详细的操作步骤、日志、截图,否则很难排查。
获取后端错误
docker ps -a查看所有容器运行状态,检查是否全部 running,如有异常,尝试docker logs 容器名查看对应日志。- 容器都运行正常的,
docker logs 容器名查看报错日志
前端错误
前端报错时,页面会出现崩溃,并提示检查控制台日志。可以打开浏览器控制台,并查看console中的 log 日志。还可以点击对应 log 的超链接,会提示到具体错误文件,可以把这些详细错误信息提供,方便排查。
OneAPI 错误
带有requestId的,都是 OneAPI 提示错误,大部分都是因为模型接口报错。可以参考 OneAPI 常见错误
二、通用问题
前端页面崩溃
- 90% 情况是模型配置不正确:确保每类模型都至少有一个启用;检查模型中一些
对象参数是否异常(数组和对象),如果为空,可以尝试给个空数组或空对象。 - 少部分是由于浏览器兼容问题,由于项目中包含一些高阶语法,可能低版本浏览器不兼容,可以将具体操作步骤和控制台中错误信息提供 issue。
- 关闭浏览器翻译功能,如果浏览器开启了翻译,可能会导致页面崩溃。
通过sealos部署的话,是否没有本地部署的一些限制?
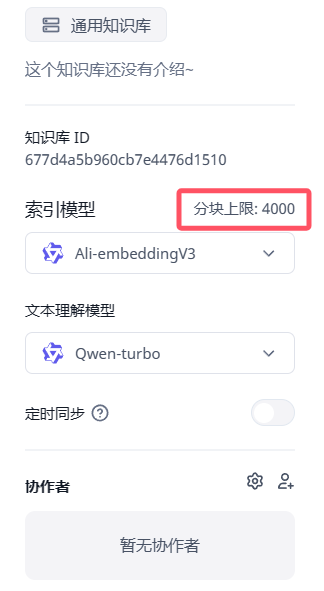 这是索引模型的长度限制,通过任何方式部署都一样的,但不同索引模型的配置不一样,可以在后台修改参数。
这是索引模型的长度限制,通过任何方式部署都一样的,但不同索引模型的配置不一样,可以在后台修改参数。
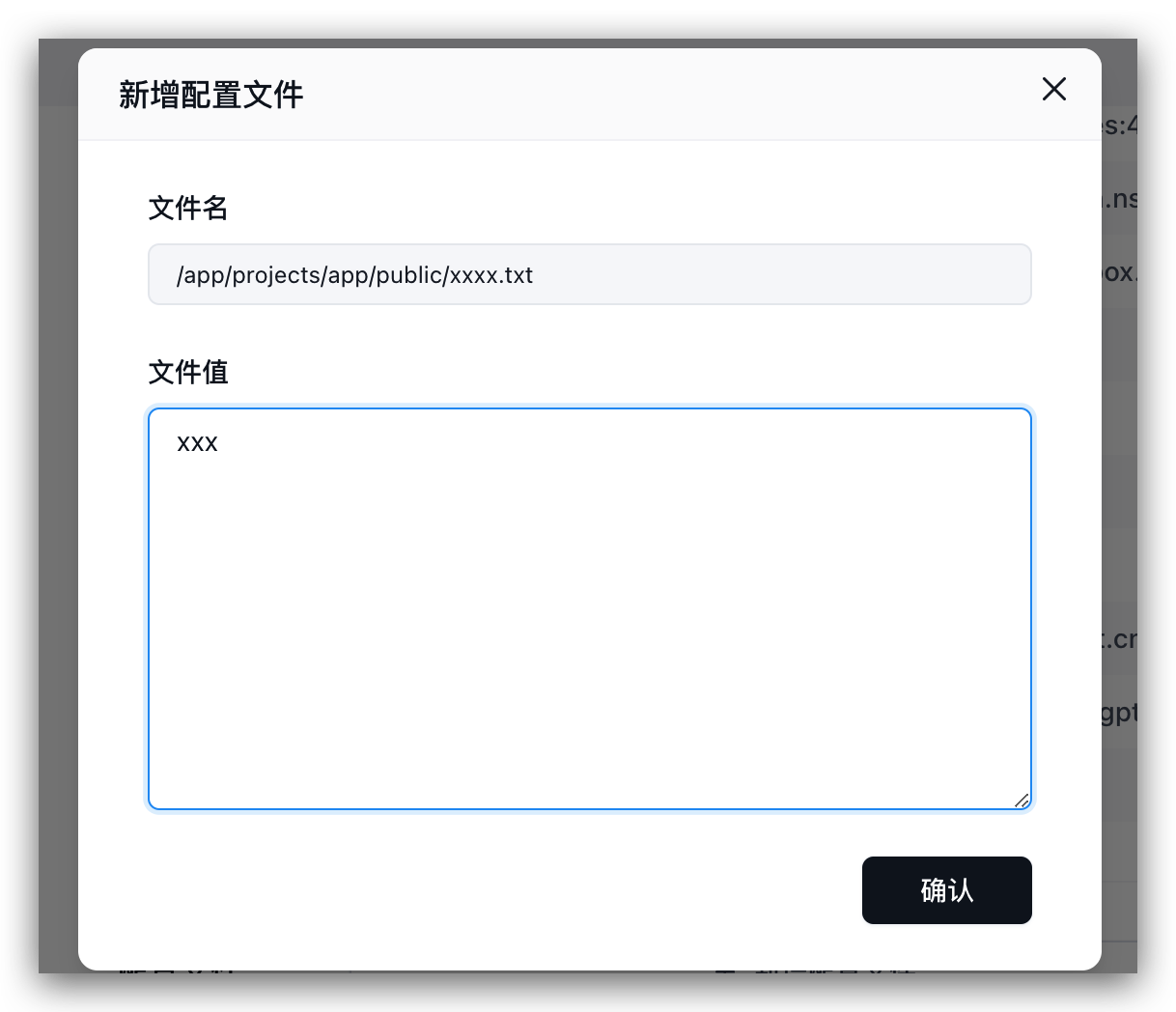
怎么挂载小程序配置文件
将验证文件,挂载到指定位置:/app/projects/app/public/xxxx.txt
然后重启。例如:
数据库3306端口被占用了,启动服务失败
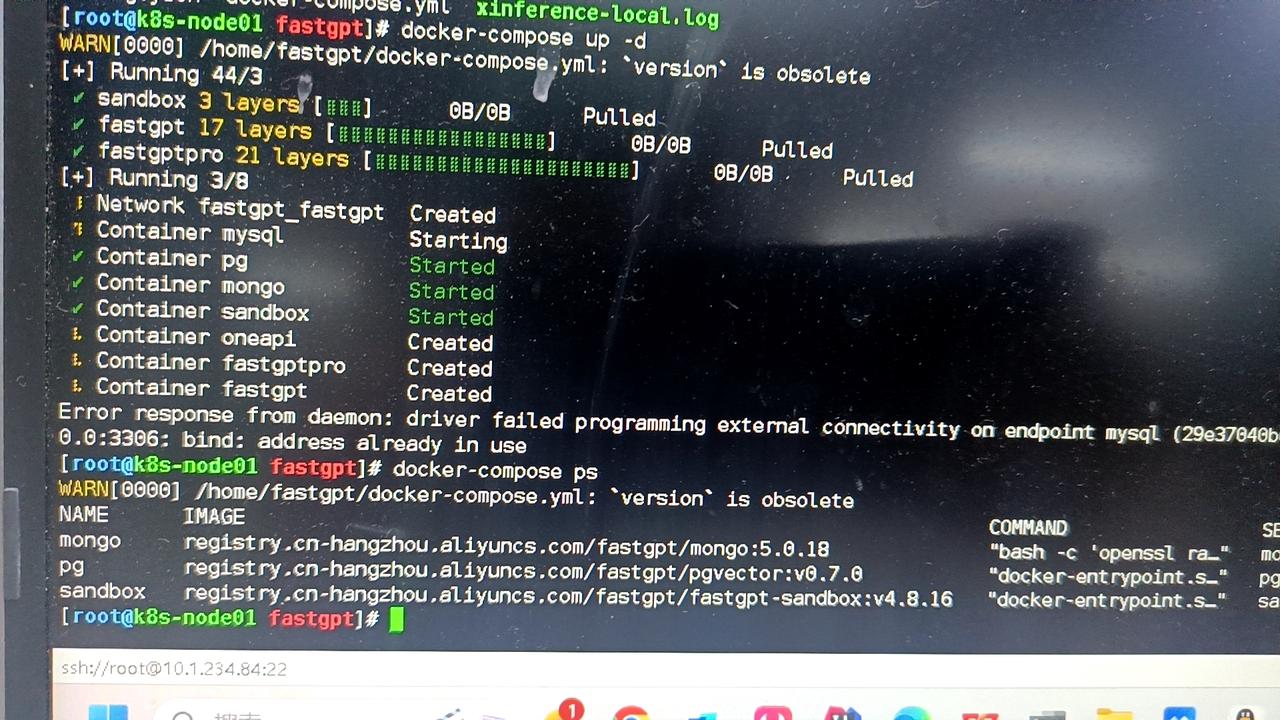
把端口映射改成 3307 之类的,例如 3307:3306。
本地部署的限制
具体内容参考https://fael3z0zfze.feishu.cn/wiki/OFpAw8XzAi36Guk8dfucrCKUnjg。
能否纯本地运行
可以。需要准备好向量模型和LLM模型。
其他模型没法进行内容提取
看日志。如果提示 JSON invalid,not support tool 之类的,说明该模型不支持工具调用或函数调用,需要设置toolChoice=false和functionCall=false,就会默认走提示词模式。目前内置提示词仅针对了商业模型API进行测试。问题分类基本可用,内容提取不太行。
页面崩溃
- 关闭翻译
- 检查配置文件是否正常加载,如果没有正常加载会导致缺失系统信息,在某些操作下会导致空指针。
- 95%情况是配置文件不对。会提示 xxx undefined
- 提示
URI malformed,请 Issue 反馈具体操作和页面,这是由于特殊字符串编码解析报错。
- 某些api不兼容问题(较少)
开启内容补全后,响应速度变慢
- 问题补全需要经过一轮AI生成。
- 会进行3~5轮的查询,如果数据库性能不足,会有明显影响。
页面中可以正常回复,API 报错
页面中是用 stream=true 模式,所以API也需要设置 stream=true 来进行测试。部分模型接口(国产居多)非 Stream 的兼容有点垃圾。 和上一个问题一样,curl 测试。
知识库索引没有进度/索引很慢
先看日志报错信息。有以下几种情况:
- 可以对话,但是索引没有进度:没有配置向量模型(vectorModels)
- 不能对话,也不能索引:API调用失败。可能是没连上OneAPI或OpenAI
- 有进度,但是非常慢:api key不行,OpenAI的免费号,一分钟只有3次还是60次。一天上限200次。
Connection error
网络异常。国内服务器无法请求OpenAI,自行检查与AI模型的连接是否正常。
或者是FastGPT请求不到 OneAPI(没放同一个网络)
修改了 vectorModels 但是没有生效
- 重启容器,确保模型配置已经加载(可以在日志或者新建知识库时候看到新模型)
- 记得刷新一次浏览器。
- 如果是已经创建的知识库,需要删除重建。向量模型是创建时候绑定的,不会动态更新。
三、常见的 OneAPI 错误
带有 requestId 的都是 OneAPI 的报错。
insufficient_user_quota user quota is not enough
OneAPI 账号的余额不足,默认 root 用户只有 200 刀,可以手动修改。
路径:打开OneAPI -> 用户 -> root用户右边的编辑 -> 剩余余额调大
xxx渠道找不到
FastGPT 模型配置文件中的 model 必须与 OneAPI 渠道中的模型对应上,否则就会提示这个错误。可检查下面内容:
- OneAPI 中没有配置该模型渠道,或者被禁用了。
- FastGPT 配置文件有 OneAPI 没有配置的模型。如果 OneAPI 没有配置对应模型的,配置文件中也不要写。
- 使用旧的向量模型创建了知识库,后又更新了向量模型。这时候需要删除以前的知识库,重建。
如果OneAPI中,没有配置对应的模型,config.json中也不要配置,否则容易报错。
点击模型测试失败
OneAPI 只会测试渠道的第一个模型,并且只会测试对话模型,向量模型无法自动测试,需要手动发起请求进行测试。查看测试模型命令示例
get request url failed: Post “https://xxx dial tcp: xxxx
OneAPI 与模型网络不通,需要检查网络配置。
Incorrect API key provided: sk-xxxx.You can find your api Key at xxx
OneAPI 的 API Key 配置错误,需要修改OPENAI_API_KEY环境变量,并重启容器(先 docker-compose down 然后再 docker-compose up -d 运行一次)。
可以exec进入容器,env查看环境变量是否生效。
bad_response_status_code bad response status code 503
- 模型服务不可用
- 模型接口参数异常(温度、max token等可能不适配)
- ….
Tiktoken 下载失败
由于 OneAPI 会在启动时从网络下载一个 tiktoken 的依赖,如果网络异常,就会导致启动失败。可以参考OneAPI 离线部署解决。
四、常见模型问题
如何检查模型可用性问题
- 私有部署模型,先确认部署的模型是否正常。
- 通过 CURL 请求,直接测试上游模型是否正常运行(云端模型或私有模型均进行测试)
- 通过 CURL 请求,请求 OneAPI 去测试模型是否正常。
- 在 FastGPT 中使用该模型进行测试。
下面是几个测试 CURL 示例:
报错 - 模型响应为空/模型报错
该错误是由于 stream 模式下,oneapi 直接结束了流请求,并且未返回任何内容导致。
4.8.10 版本新增了错误日志,报错时,会在日志中打印出实际发送的 Body 参数,可以复制该参数后,通过 curl 向 oneapi 发起请求测试。
由于 oneapi 在 stream 模式下,无法正确捕获错误,有时候可以设置成 stream=false 来获取到精确的错误。
可能的报错问题:
- 国内模型命中风控
- 不支持的模型参数:只保留 messages 和必要参数来测试,删除其他参数测试。
- 参数不符合模型要求:例如有的模型 temperature 不支持 0,有些不支持两位小数。max_tokens 超出,上下文超长等。
- 模型部署有问题,stream 模式不兼容。
测试示例如下,可复制报错日志中的请求体进行测试:
curl --location --request POST 'https://api.openai.com/v1/chat/completions' \
--header 'Authorization: Bearer sk-xxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "xxx",
"temperature": 0.01,
"max_tokens": 1000,
"stream": true,
"messages": [
{
"role": "user",
"content": " 你是饿"
}
]
}'
如何测试模型是否支持工具调用
需要模型提供商和 oneapi 同时支持工具调用才可使用,测试方法如下:
1. 通过 curl 向 oneapi 发起第一轮 stream 模式的 tool 测试。
curl --location --request POST 'https://oneapi.xxx/v1/chat/completions' \
--header 'Authorization: Bearer sk-xxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "gpt-4o-mini",
"temperature": 0.01,
"max_tokens": 8000,
"stream": true,
"messages": [
{
"role": "user",
"content": "几点了"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "hCVbIY",
"description": "获取用户当前时区的时间。",
"parameters": {
"type": "object",
"properties": {},
"required": []
}
}
}
],
"tool_choice": "auto"
}'
2. 检查响应参数
如果能正常调用工具,会返回对应 tool_calls 参数。
{
"id": "chatcmpl-A7kwo1rZ3OHYSeIFgfWYxu8X2koN3",
"object": "chat.completion.chunk",
"created": 1726412126,
"model": "gpt-4o-mini-2024-07-18",
"system_fingerprint": "fp_483d39d857",
"choices": [
{
"index": 0,
"delta": {
"role": "assistant",
"content": null,
"tool_calls": [
{
"index": 0,
"id": "call_0n24eiFk8OUyIyrdEbLdirU7",
"type": "function",
"function": {
"name": "mEYIcFl84rYC",
"arguments": ""
}
}
],
"refusal": null
},
"logprobs": null,
"finish_reason": null
}
],
"usage": null
}
3. 通过 curl 向 oneapi 发起第二轮 stream 模式的 tool 测试。
第二轮请求是把工具结果发送给模型。发起后会得到模型回答的结果。
curl --location --request POST 'https://oneapi.xxxx/v1/chat/completions' \
--header 'Authorization: Bearer sk-xxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"model": "gpt-4o-mini",
"temperature": 0.01,
"max_tokens": 8000,
"stream": true,
"messages": [
{
"role": "user",
"content": "几点了"
},
{
"role": "assistant",
"tool_calls": [
{
"id": "kDia9S19c4RO",
"type": "function",
"function": {
"name": "hCVbIY",
"arguments": "{}"
}
}
]
},
{
"tool_call_id": "kDia9S19c4RO",
"role": "tool",
"name": "hCVbIY",
"content": "{\n \"time\": \"2024-09-14 22:59:21 Sunday\"\n}"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "hCVbIY",
"description": "获取用户当前时区的时间。",
"parameters": {
"type": "object",
"properties": {},
"required": []
}
}
}
],
"tool_choice": "auto"
}'
向量检索得分大于 1
由于模型没有归一化导致的。目前仅支持归一化的模型。