FastGPT 模型配置说明
FastGPT 模型配置说明
在 4.8.20 版本以前,FastGPT 模型配置在 config.json 文件中声明,你可以在 https://github.com/labring/FastGPT/blob/main/projects/app/data/model.json 中找到旧版的配置文件示例。
从 4.8.20 版本开始,你可以直接在 FastGPT 页面中进行模型配置,并且系统内置了大量模型,无需从 0 开始配置。下面介绍模型配置的基本流程:
配置模型
1. 对接模型提供商
AI Proxy
从 4.8.23 版本开始, FastGPT 支持在页面上配置模型提供商,即使用 AI Proxy 接入教程 来进行模型聚合,从而可以对接更多模型提供商。
One API
也可以使用 OneAPI 接入教程。你需要先在各服务商申请好 API 接入 OneAPI 后,才能在 FastGPT 中使用这些模型。示例流程如下:
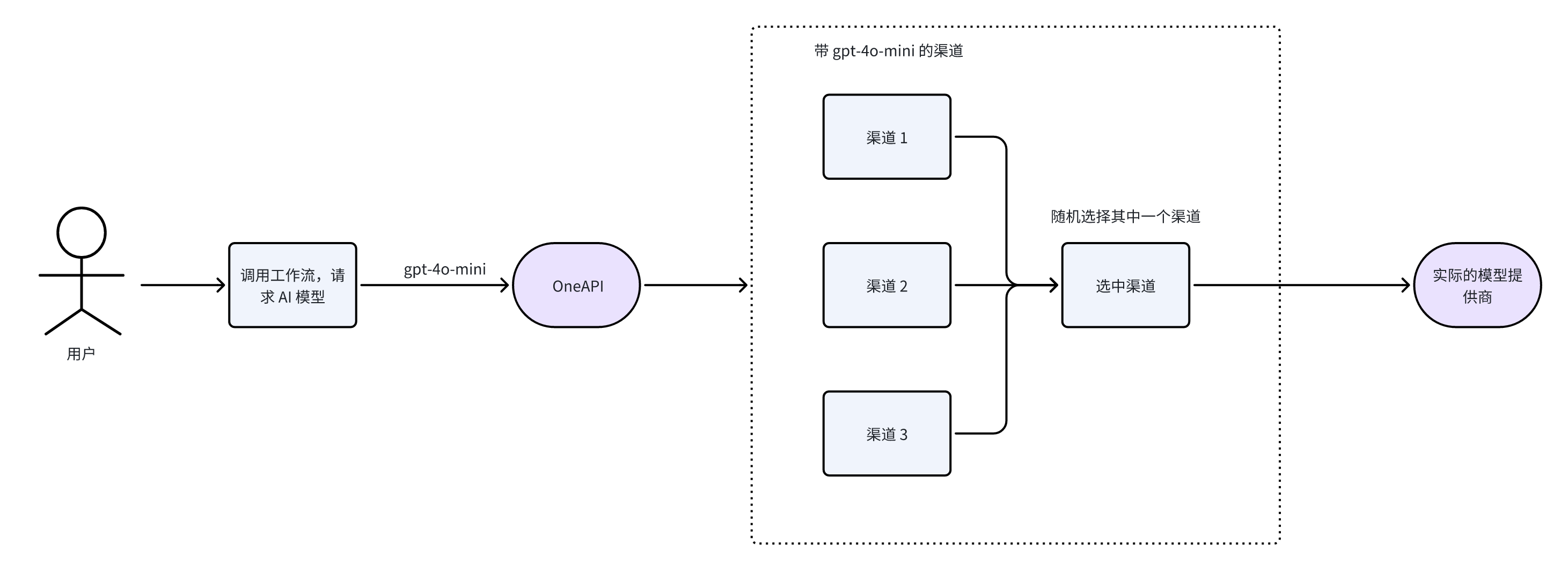
除了各模型官方的服务外,还有一些第三方服务商提供模型接入服务,当然你也可以用 Ollama 等来部署本地模型,最终都需要接入 OneAPI,下面是一些第三方服务商:
SiliconCloud(硅基流动): 提供开源模型调用的平台。
Sealos AIProxy: 提供国内各家模型代理,无需逐一申请 api。
在 OneAPI 配置好模型后,你就可以打开 FastGPT 页面,启用对应模型了。
2. 配置介绍
注意:
- 目前语音识别模型和重排模型仅会生效一个,所以配置时候,只需要配置一个即可。
- 系统至少需要一个语言模型和一个索引模型才能正常使用。
核心配置
- 模型 ID:接口请求时候,Body 中
model字段的值,全局唯一。 - 自定义请求地址/Key:如果需要绕过
OneAPI,可以设置自定义请求地址和 Token。一般情况下不需要,如果 OneAPI 不支持某些模型,可以使用该特性。
模型类型
- 语言模型 - 进行文本对话,多模态模型支持图片识别。
- 索引模型 - 对文本块进行索引,用于相关文本检索。
- 重排模型 - 对检索结果进行重排,用于优化检索排名。
- 语音合成 - 将文本转换为语音。
- 语音识别 - 将语音转换为文本。
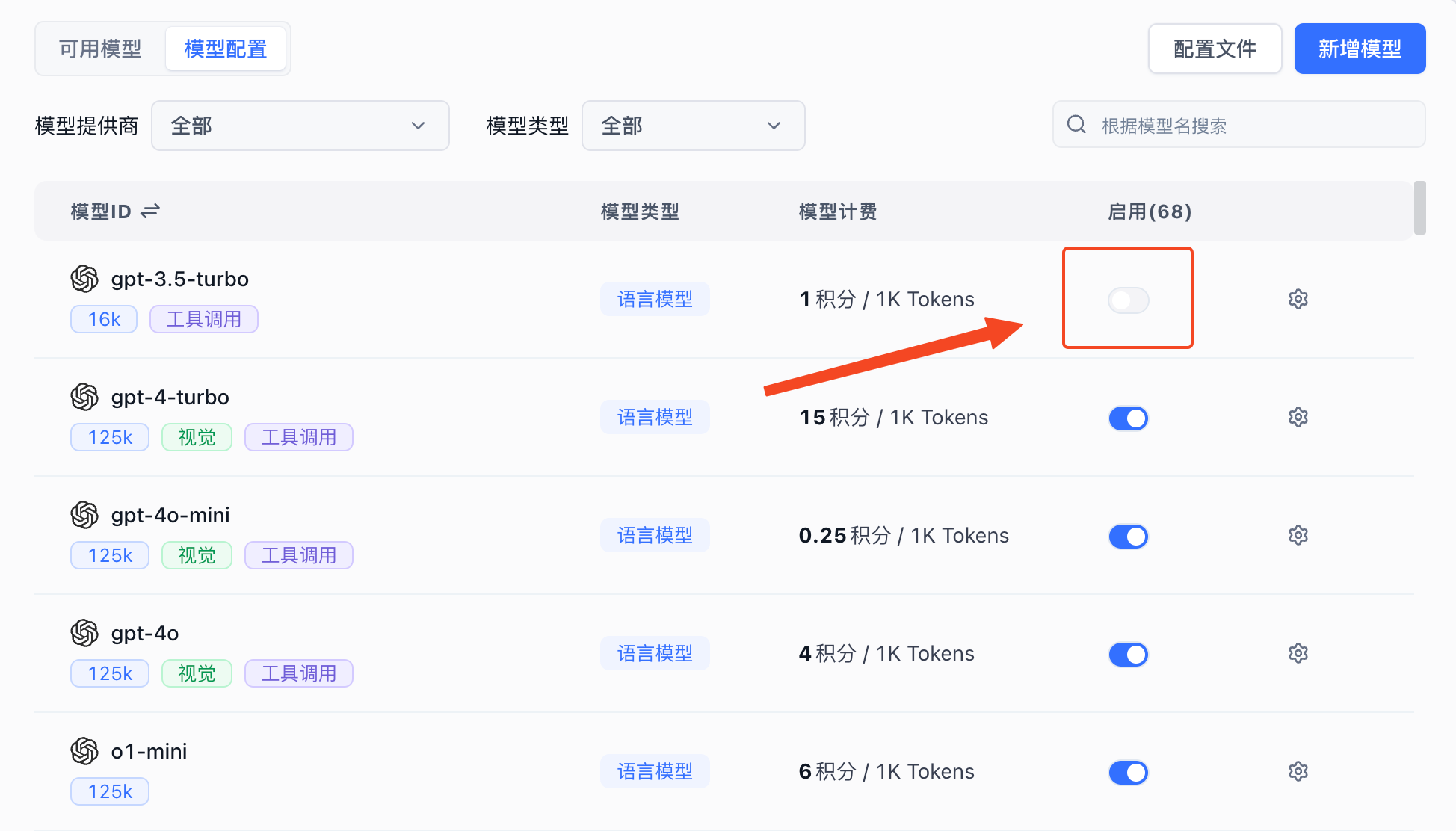
启用模型
系统内置了目前主流厂商的模型,如果你不熟悉配置,直接点击启用即可,需要注意的是,模型 ID需要和 OneAPI 中渠道的模型一致。
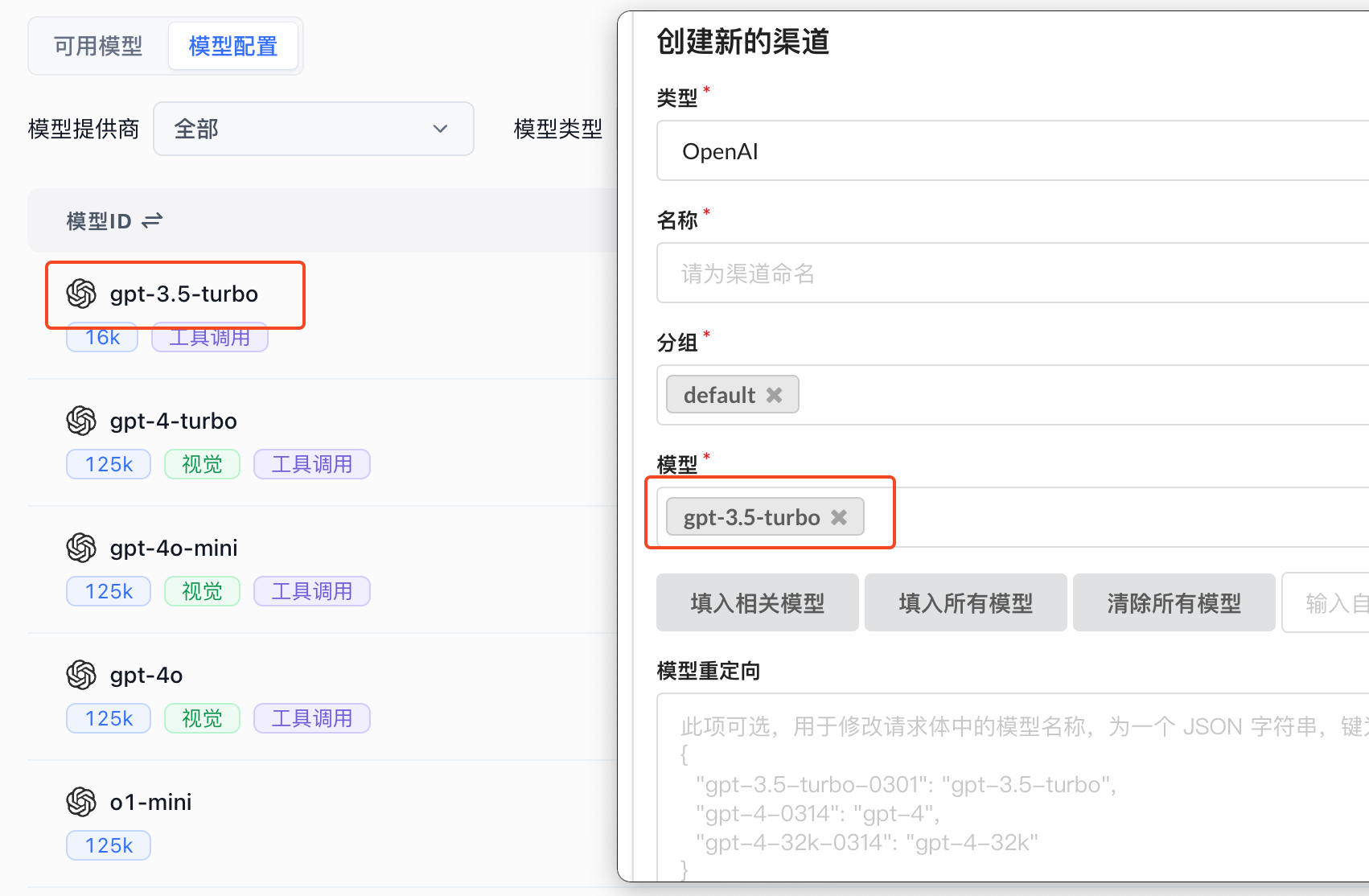 |  |
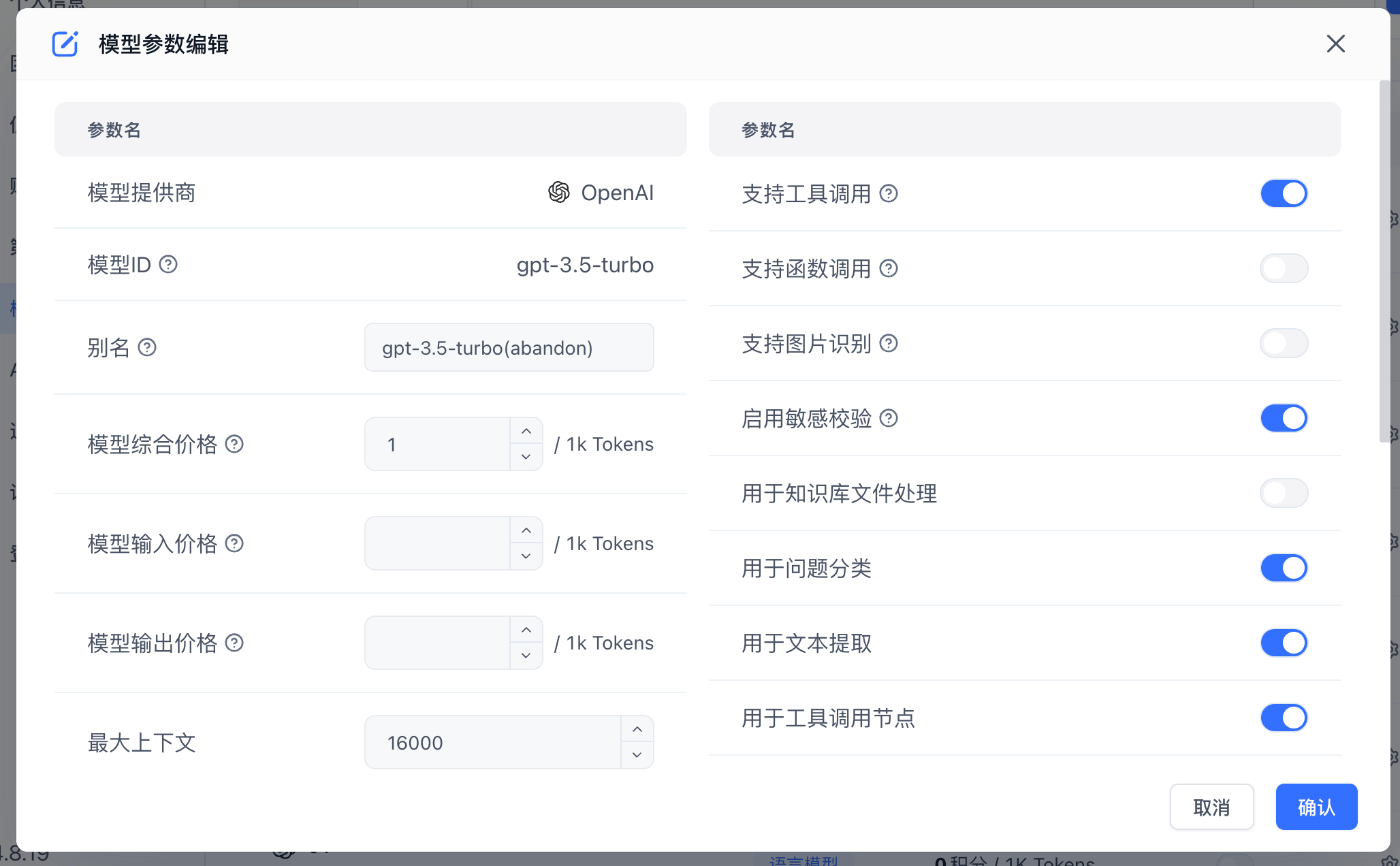
修改模型配置
点击模型右侧的齿轮即可进行模型配置,不同类型模型的配置有区别。
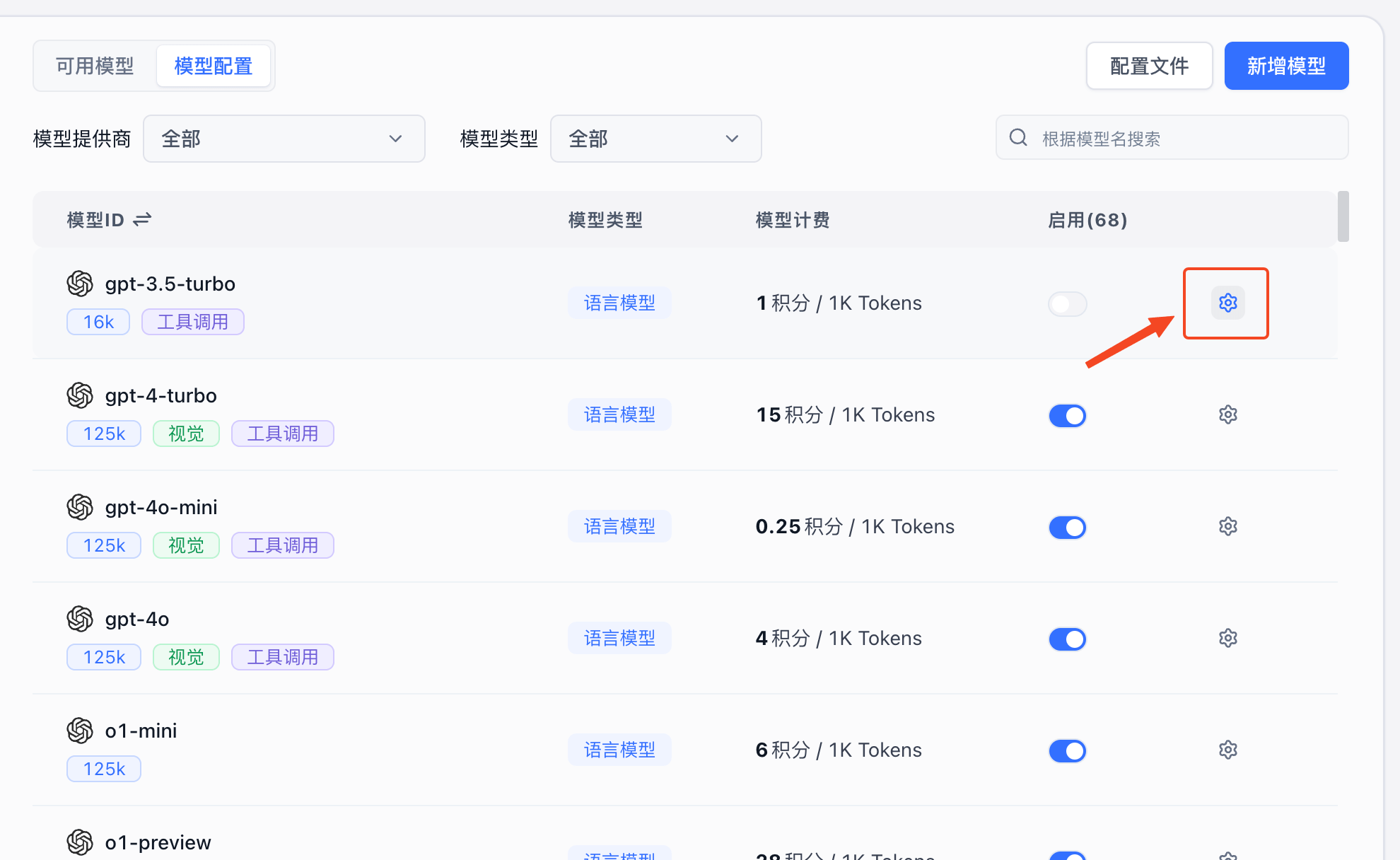 |  |
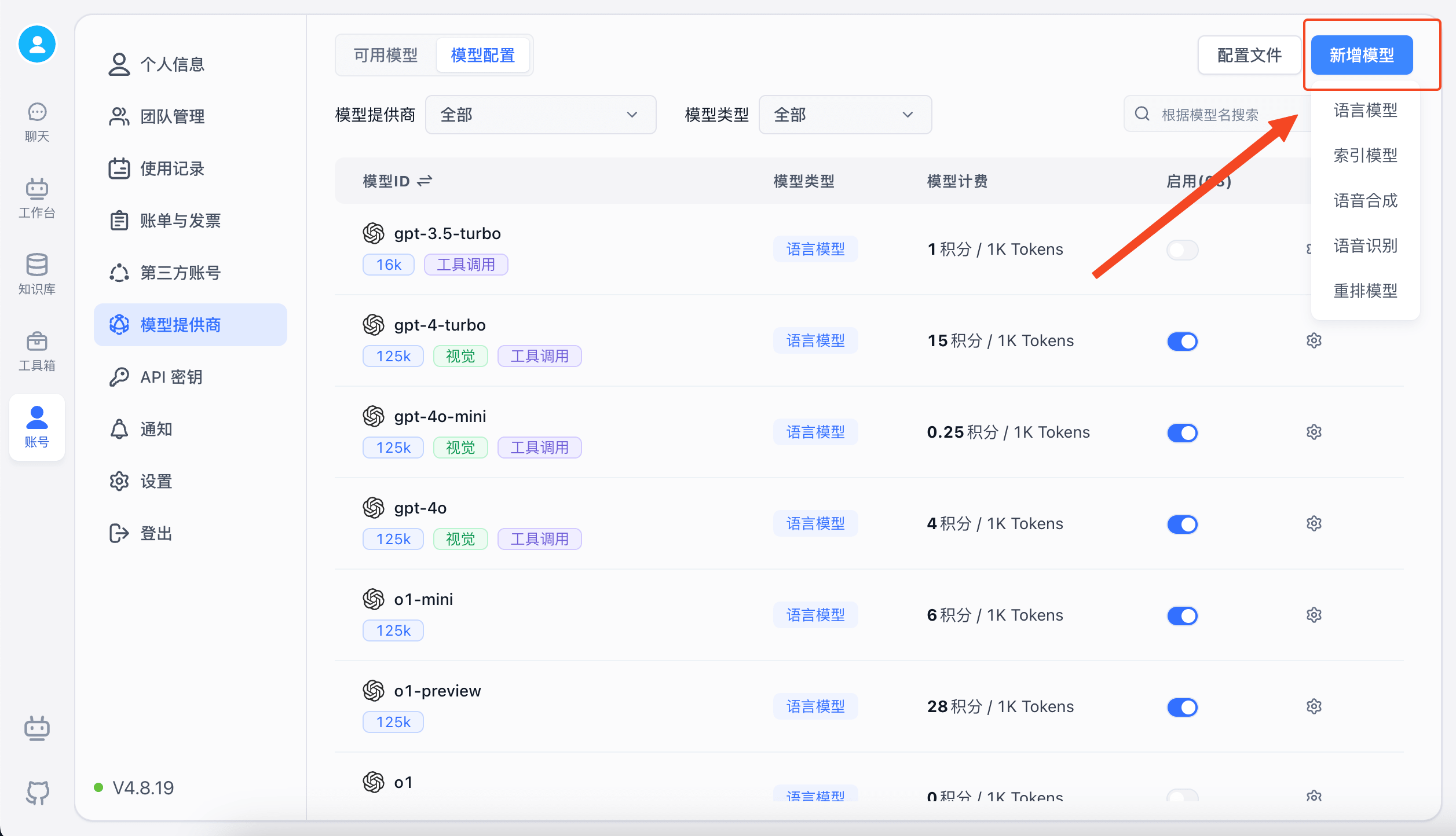
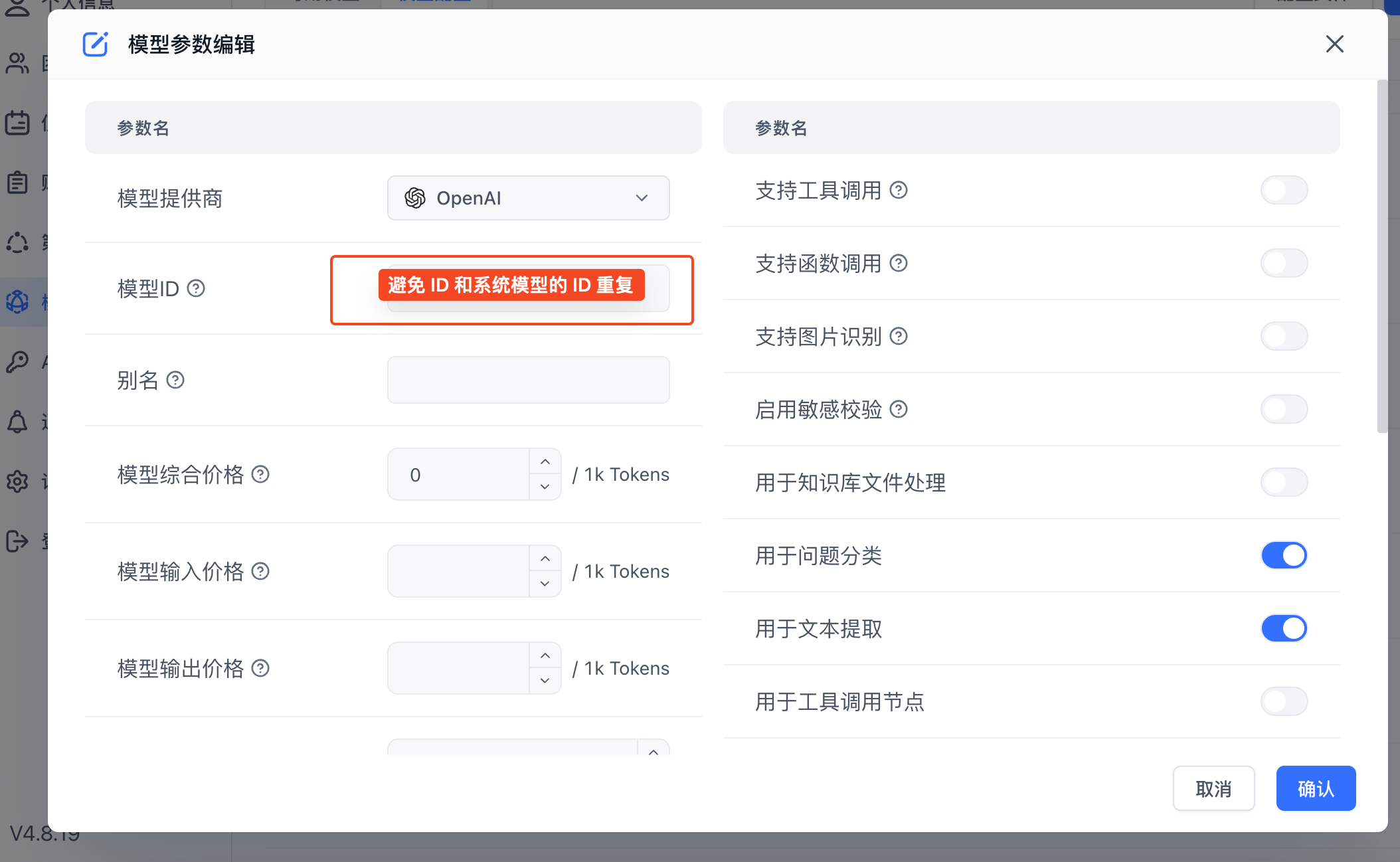
新增自定义模型
如果系统内置的模型无法满足你的需求,你可以添加自定义模型。自定义模型中,如果模型 ID与系统内置的模型 ID 一致,则会被认为是修改系统模型。
 |  |
通过配置文件配置
如果你觉得通过页面配置模型比较麻烦,你也可以通过配置文件来配置模型。或者希望快速将一个系统的配置,复制到另一个系统,也可以通过配置文件来实现。
 | 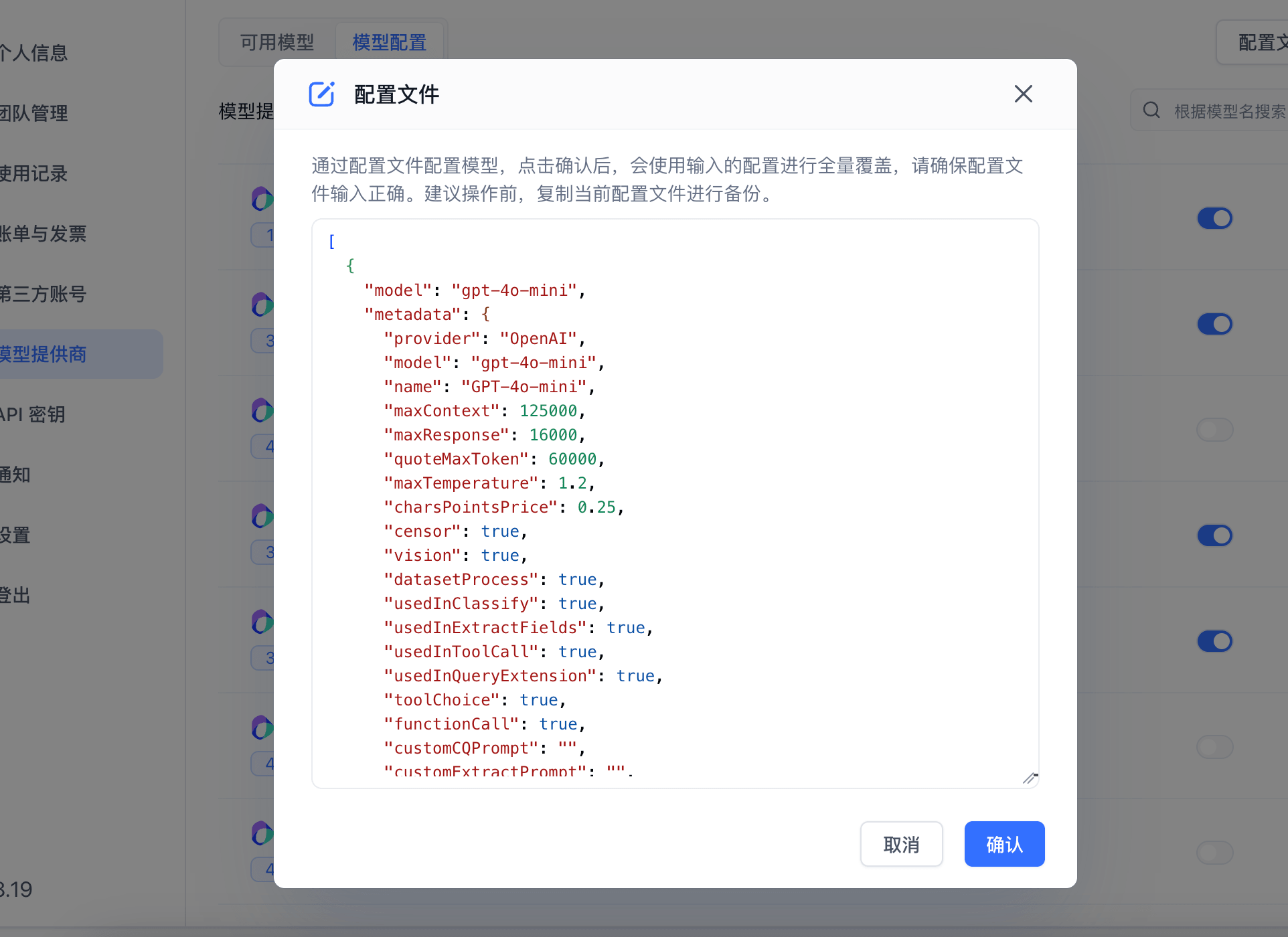 |
语言模型字段说明:
{
"model": "模型 ID",
"metadata": {
"isCustom": true, // 是否为自定义模型
"isActive": true, // 是否启用
"provider": "OpenAI", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
"model": "gpt-4o-mini", // 模型ID(对应OneAPI中渠道的模型名)
"name": "gpt-4o-mini", // 模型别名
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
}
}
索引模型字段说明:
{
"model": "模型 ID",
"metadata": {
"isCustom": true, // 是否为自定义模型
"isActive": true, // 是否启用
"provider": "OpenAI", // 模型提供商
"model": "text-embedding-3-small", // 模型ID
"name": "text-embedding-3-small", // 模型别名
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 512, // 默认文本分割时候的 token
"maxToken": 3000 // 最大 token
}
}
重排模型字段说明:
{
"model": "模型 ID",
"metadata": {
"isCustom": true, // 是否为自定义模型
"isActive": true, // 是否启用
"provider": "BAAI", // 模型提供商
"model": "bge-reranker-v2-m3", // 模型ID
"name": "ReRanker-Base", // 模型别名
"requestUrl": "", // 自定义请求地址
"requestAuth": "", // 自定义请求认证
"type": "rerank" // 模型类型
}
}
语音合成模型字段说明:
{
"model": "模型 ID",
"metadata": {
"isActive": true, // 是否启用
"isCustom": true, // 是否为自定义模型
"type": "tts", // 模型类型
"provider": "FishAudio", // 模型提供商
"model": "fishaudio/fish-speech-1.5", // 模型ID
"name": "fish-speech-1.5", // 模型别名
"voices": [ // 音色
{
"label": "fish-alex", // 音色名称
"value": "fishaudio/fish-speech-1.5:alex", // 音色ID
},
{
"label": "fish-anna", // 音色名称
"value": "fishaudio/fish-speech-1.5:anna", // 音色ID
}
],
"charsPointsPrice": 0 // n积分/1k token
}
}
语音识别模型字段说明:
{
"model": "whisper-1",
"metadata": {
"isActive": true, // 是否启用
"isCustom": true, // 是否为自定义模型
"provider": "OpenAI", // 模型提供商
"model": "whisper-1", // 模型ID
"name": "whisper-1", // 模型别名
"charsPointsPrice": 0, // n积分/1k token
"type": "stt" // 模型类型
}
}
模型测试
FastGPT 页面上提供了每类模型的简单测试,可以初步检查模型是否正常工作,会实际按模板发送一个请求。
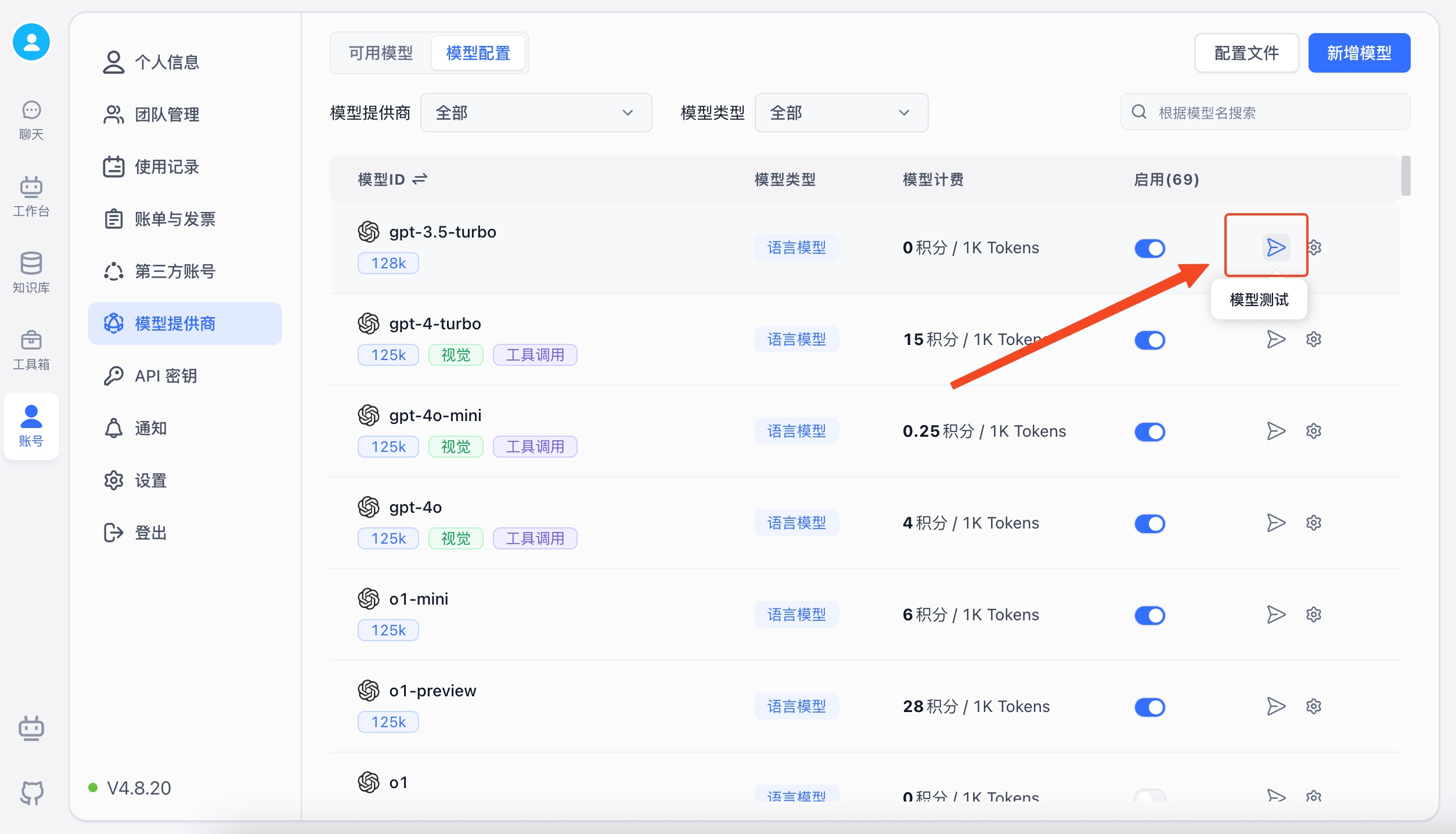
特殊接入示例
ReRank 模型接入
由于 OneAPI 不支持 Rerank 模型,所以需要单独配置。FastGPT 中,模型配置支持自定义请求地址,可以绕过 OneAPI,直接向提供商发起请求,可以利用这个特性来接入 Rerank 模型。
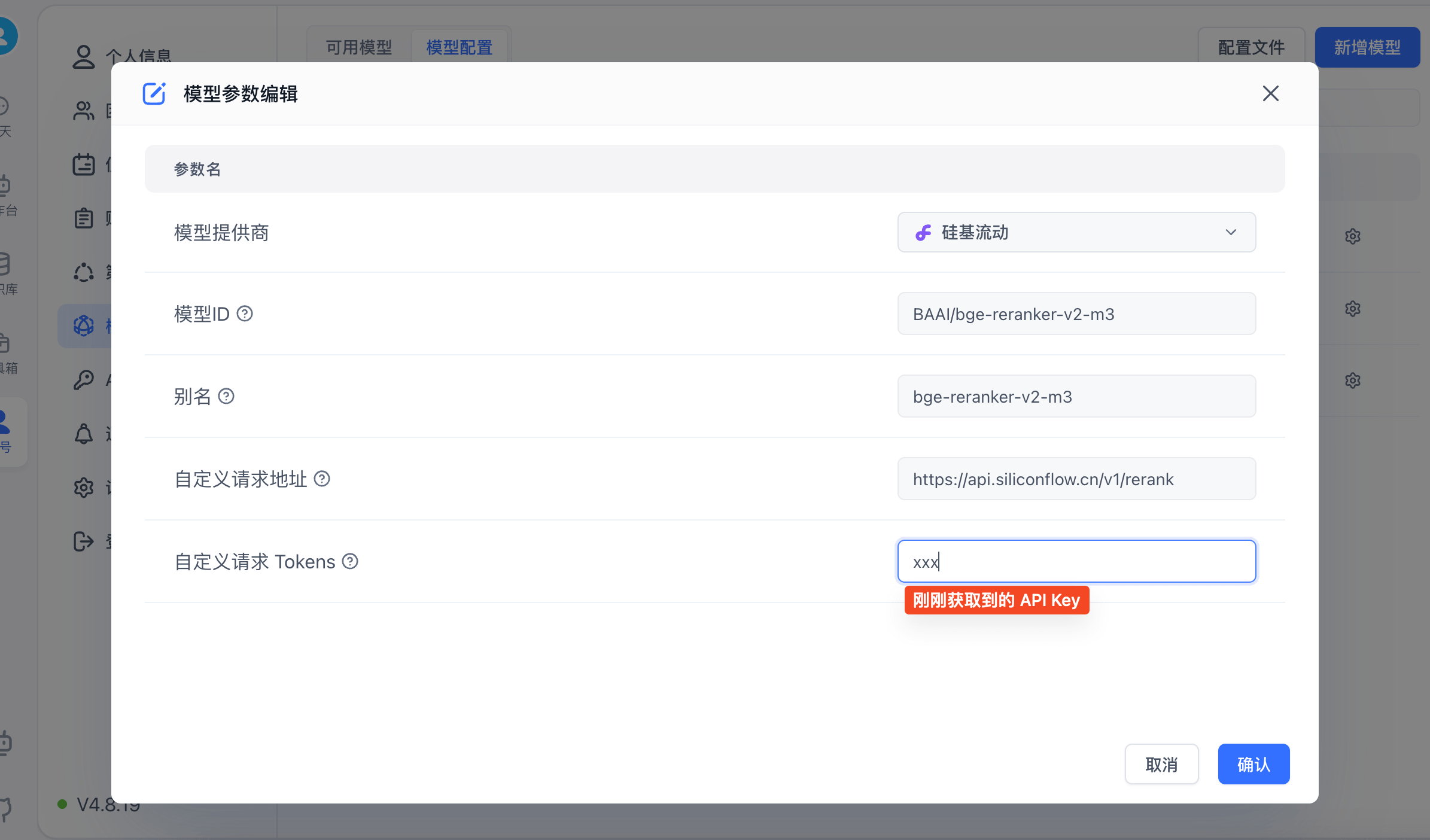
使用硅基流动的在线模型
有免费的 bge-reranker-v2-m3 模型可以使用。
- 点击注册硅基流动账号
- 进入控制台,获取 API key: https://cloud.siliconflow.cn/account/ak
- 打开 FastGPT 模型配置,新增一个
BAAI/bge-reranker-v2-m3的重排模型(如果系统内置了,也可以直接变更,无需新增)。
私有部署模型
接入语音识别模型
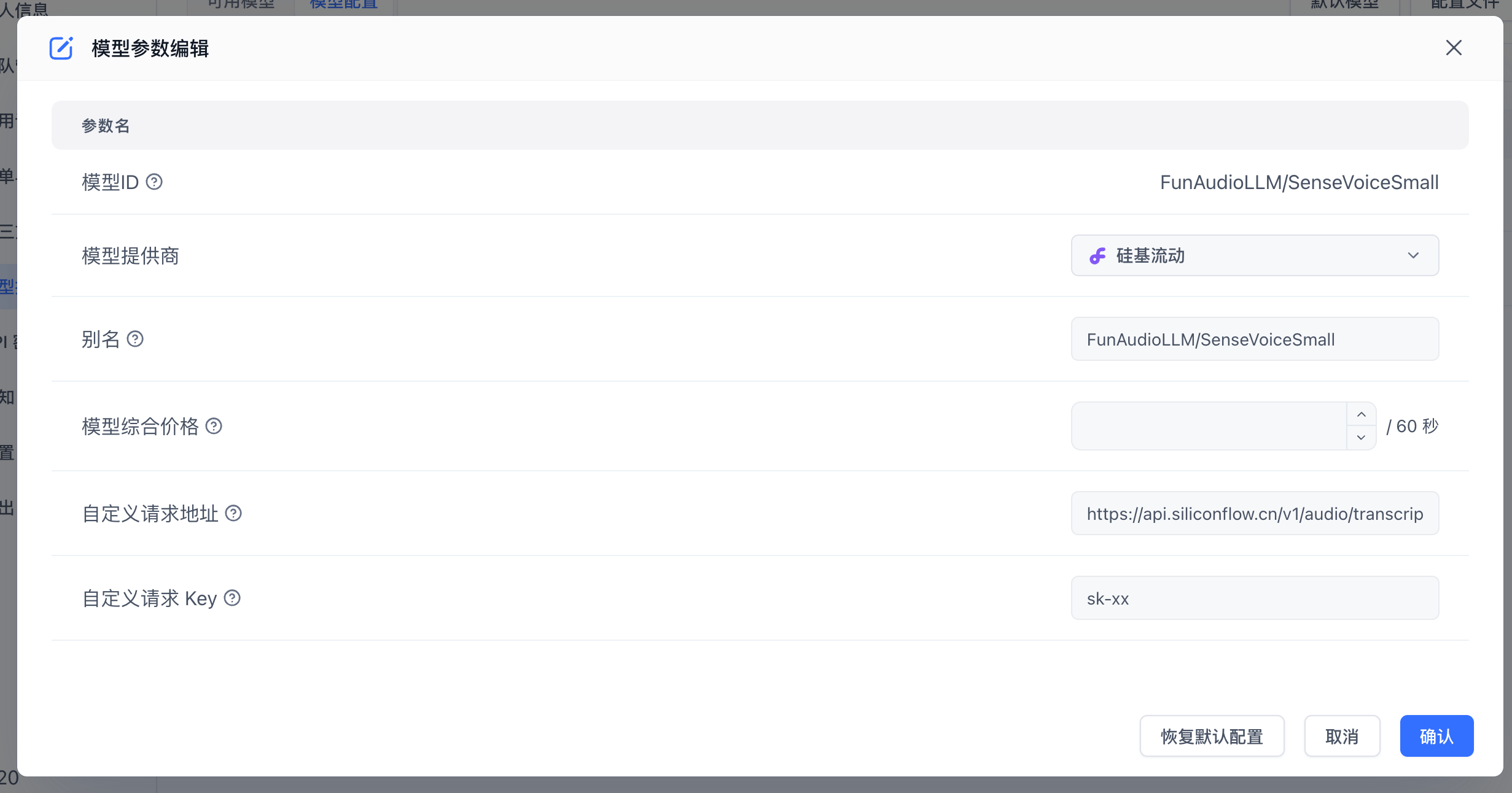
OneAPI 的语言识别接口,无法正确的识别其他模型(会始终识别成 whisper-1),所以如果想接入其他模型,可以通过自定义请求地址来实现。例如,接入硅基流动的 FunAudioLLM/SenseVoiceSmall 模型,可以参考如下配置:
点击模型编辑:
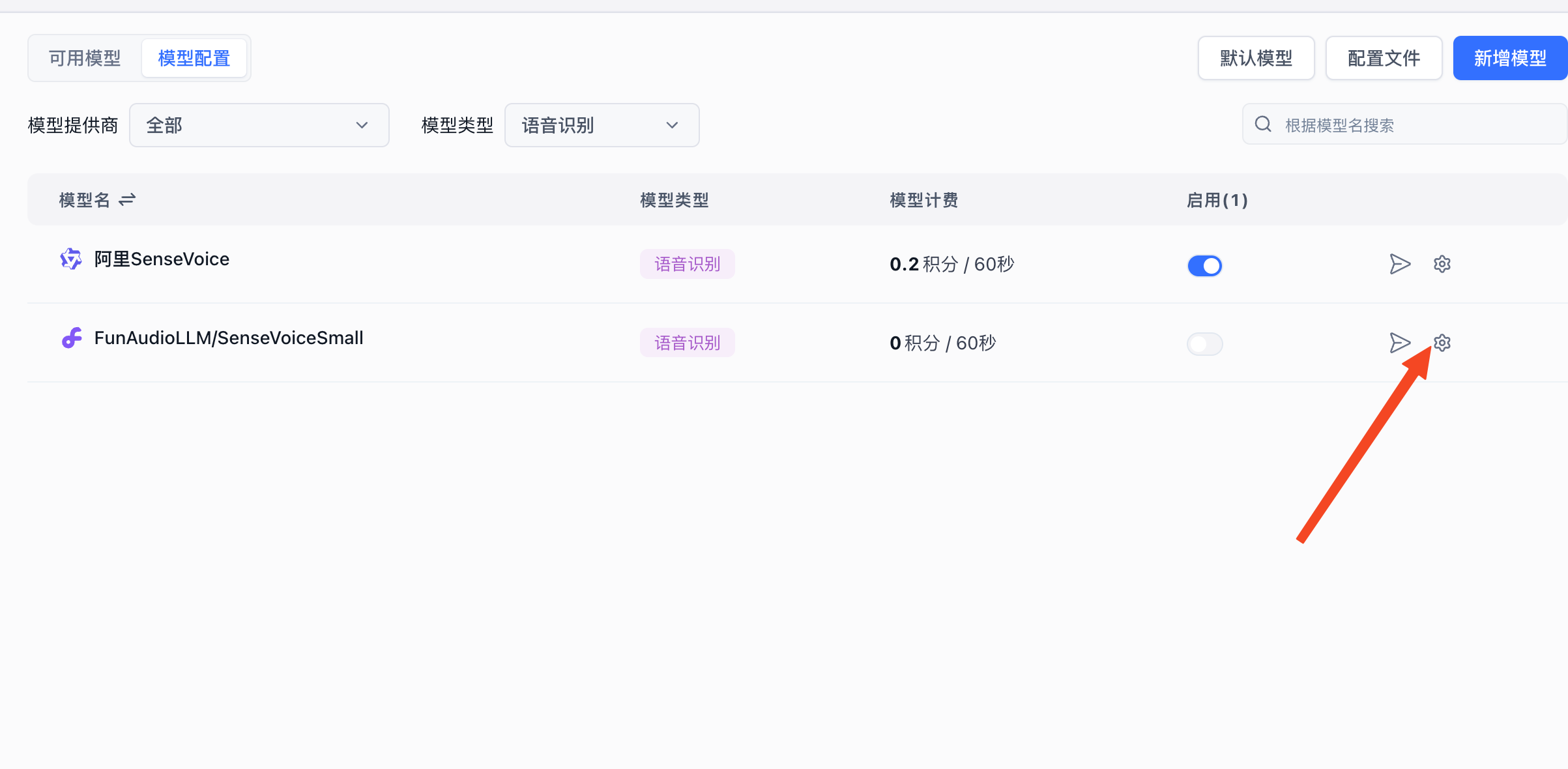
填写硅基流动的地址:https://api.siliconflow.cn/v1/audio/transcriptions,并填写硅基流动的 API Key。
其他配置项说明
自定义请求地址
如果填写了该值,则可以允许你绕过 OneAPI,直接向自定义请求地址发起请求。需要填写完整的请求地址,例如:
- LLM: {{host}}/v1/chat/completions
- Embedding: {{host}}/v1/embeddings
- STT: {{host}}/v1/audio/transcriptions
- TTS: {{host}}/v1/audio/speech
- Rerank: {{host}}/v1/rerank
自定义请求 Key,则是向自定义请求地址发起请求时候,携带请求头:Authorization: Bearer xxx 进行请求。
所有接口均遵循 OpenAI 提供的模型格式,可参考 OpenAI API 文档 进行配置。
由于 OpenAI 没有提供 ReRank 模型,遵循的是 Cohere 的格式。点击查看接口请求示例
模型价格配置
商业版用户可以通过配置模型价格,来进行账号计费。系统包含两种计费模式:按总 tokens 计费和输入输出 Tokens 分开计费。
如果需要配置输入输出 Tokens 分开计费模式,则填写模型输入价格和模型输出价格两个值。
如果需要配置按总 tokens 计费模式,则填写模型综合价格一个值。
如何提交内置模型
由于模型更新非常频繁,官方不一定及时更新,如果未能找到你期望的内置模型,你可以提交 Issue,提供模型的名字和对应官网。或者直接提交 PR,提供模型配置。
添加模型提供商
如果你需要添加模型提供商,需要修改以下代码:
- FastGPT/packages/web/components/common/Icon/icons/model - 在此目录下,添加模型提供商的 svg 头像地址。
- 在 FastGPT 根目录下,运行
pnpm initIcon,将图片加载到配置文件中。 - FastGPT/packages/global/core/ai/provider.ts - 在此文件中,追加模型提供商的配置。
添加模型
你可以在FastGPT/packages/service/core/ai/config/provider目录下,找对应模型提供商的配置文件,并追加模型配置。请自行全文检查,model字段,必须在所有模型中唯一。具体配置字段说明,参考模型配置字段说明
旧版模型配置说明
配置好 OneAPI 后,需要在config.json文件中,手动的增加模型配置,并重启。
由于环境变量不利于配置复杂的内容,FastGPT 采用了 ConfigMap 的形式挂载配置文件,你可以在 projects/app/data/config.json 看到默认的配置文件。可以参考 docker-compose 快速部署 来挂载配置文件。
开发环境下,你需要将示例配置文件 config.json 复制成 config.local.json 文件才会生效。
Docker部署,修改config.json 文件,需要重启容器。
下面配置文件示例中包含了系统参数和各个模型配置:
{
"feConfigs": {
"lafEnv": "https://laf.dev" // laf环境。 https://laf.run (杭州阿里云) ,或者私有化的laf环境。如果使用 Laf openapi 功能,需要最新版的 laf 。
},
"systemEnv": {
"vectorMaxProcess": 15, // 向量处理线程数量
"qaMaxProcess": 15, // 问答拆分线程数量
"tokenWorkers": 50, // Token 计算线程保持数,会持续占用内存,不能设置太大。
"hnswEfSearch": 100 // 向量搜索参数,仅对 PG 和 OB 生效。越大,搜索越精确,但是速度越慢。设置为100,有99%+精度。
},
"llmModels": [
{
"provider": "OpenAI", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
"model": "gpt-4o-mini", // 模型名(对应OneAPI中渠道的模型名)
"name": "gpt-4o-mini", // 模型别名
"maxContext": 125000, // 最大上下文
"maxResponse": 16000, // 最大回复
"quoteMaxToken": 120000, // 最大引用内容
"maxTemperature": 1.2, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": true, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},
{
"provider": "OpenAI",
"model": "gpt-4o",
"name": "gpt-4o",
"maxContext": 125000,
"maxResponse": 4000,
"quoteMaxToken": 120000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {},
"fieldMap": {}
},
{
"provider": "OpenAI",
"model": "o1-mini",
"name": "o1-mini",
"maxContext": 125000,
"maxResponse": 65000,
"quoteMaxToken": 120000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": false,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"toolChoice": false,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {
"temperature": 1,
"max_tokens": null,
"stream": false
}
},
{
"provider": "OpenAI",
"model": "o1-preview",
"name": "o1-preview",
"maxContext": 125000,
"maxResponse": 32000,
"quoteMaxToken": 120000,
"maxTemperature": 1.2,
"charsPointsPrice": 0,
"censor": false,
"vision": false,
"datasetProcess": true,
"usedInClassify": true,
"usedInExtractFields": true,
"usedInToolCall": true,
"toolChoice": false,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {
"temperature": 1,
"max_tokens": null,
"stream": false
}
}
],
"vectorModels": [
{
"provider": "OpenAI",
"model": "text-embedding-3-small",
"name": "text-embedding-3-small",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100
},
{
"provider": "OpenAI",
"model": "text-embedding-3-large",
"name": "text-embedding-3-large",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 3000,
"weight": 100,
"defaultConfig": {
"dimensions": 1024
}
},
{
"provider": "OpenAI",
"model": "text-embedding-ada-002", // 模型名(与OneAPI对应)
"name": "Embedding-2", // 模型展示名
"charsPointsPrice": 0, // n积分/1k token
"defaultToken": 700, // 默认文本分割时候的 token
"maxToken": 3000, // 最大 token
"weight": 100, // 优先训练权重
"defaultConfig": {}, // 自定义额外参数。例如,如果希望使用 embedding3-large 的话,可以传入 dimensions:1024,来返回1024维度的向量。(目前必须小于1536维度)
"dbConfig": {}, // 存储时的额外参数(非对称向量模型时候需要用到)
"queryConfig": {} // 参训时的额外参数
}
],
"reRankModels": [],
"audioSpeechModels": [
{
"provider": "OpenAI",
"model": "tts-1",
"name": "OpenAI TTS1",
"charsPointsPrice": 0,
"voices": [
{ "label": "Alloy", "value": "alloy", "bufferId": "openai-Alloy" },
{ "label": "Echo", "value": "echo", "bufferId": "openai-Echo" },
{ "label": "Fable", "value": "fable", "bufferId": "openai-Fable" },
{ "label": "Onyx", "value": "onyx", "bufferId": "openai-Onyx" },
{ "label": "Nova", "value": "nova", "bufferId": "openai-Nova" },
{ "label": "Shimmer", "value": "shimmer", "bufferId": "openai-Shimmer" }
]
}
],
"whisperModel": {
"provider": "OpenAI",
"model": "whisper-1",
"name": "Whisper1",
"charsPointsPrice": 0
}
}