通过 SiliconCloud 体验开源模型
通过 SiliconCloud 体验开源模型
SiliconCloud(硅基流动) 是一个以提供开源模型调用为主的平台,并拥有自己的加速引擎。帮助用户低成本、快速的进行开源模型的测试和使用。实际体验下来,他们家模型的速度和稳定性都非常不错,并且种类丰富,覆盖语言、向量、重排、TTS、STT、绘图、视频生成模型,可以满足 FastGPT 中所有模型需求。
如果你想部分模型使用 SiliconCloud 的模型,可额外参考OneAPI接入硅基流动。
本文会介绍完全使用 SiliconCloud 模型来部署 FastGPT 的方案。
1. 注册 SiliconCloud 账号
- 点击注册硅基流动账号
- 进入控制台,获取 API key: https://cloud.siliconflow.cn/account/ak
2. 修改 FastGPT 环境变量
OPENAI_BASE_URL=https://api.siliconflow.cn/v1
# 填写 SiliconCloud 控制台提供的 Api Key
CHAT_API_KEY=sk-xxxxxx
3. 修改 FastGPT 模型配置
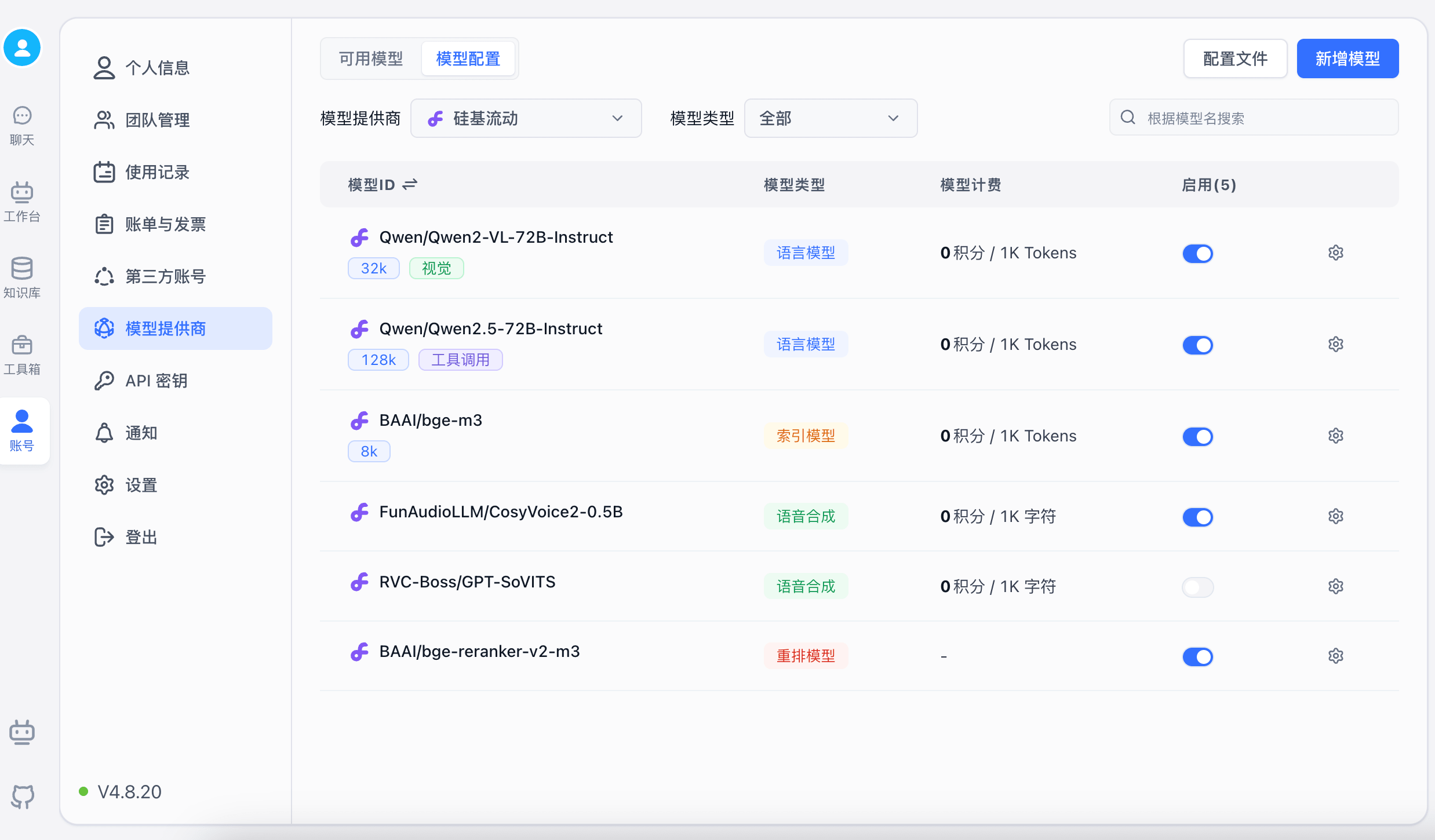
系统内置了几个硅基流动的模型进行体验,如果需要其他模型,可以手动添加。
这里启动了 Qwen2.5 72b 的纯语言和视觉模型;选择 bge-m3 作为向量模型;选择 bge-reranker-v2-m3 作为重排模型。选择 fish-speech-1.5 作为语音模型;选择 SenseVoiceSmall 作为语音输入模型。
4. 体验测试
测试对话和图片识别
随便新建一个简易应用,选择对应模型,并开启图片上传后进行测试:
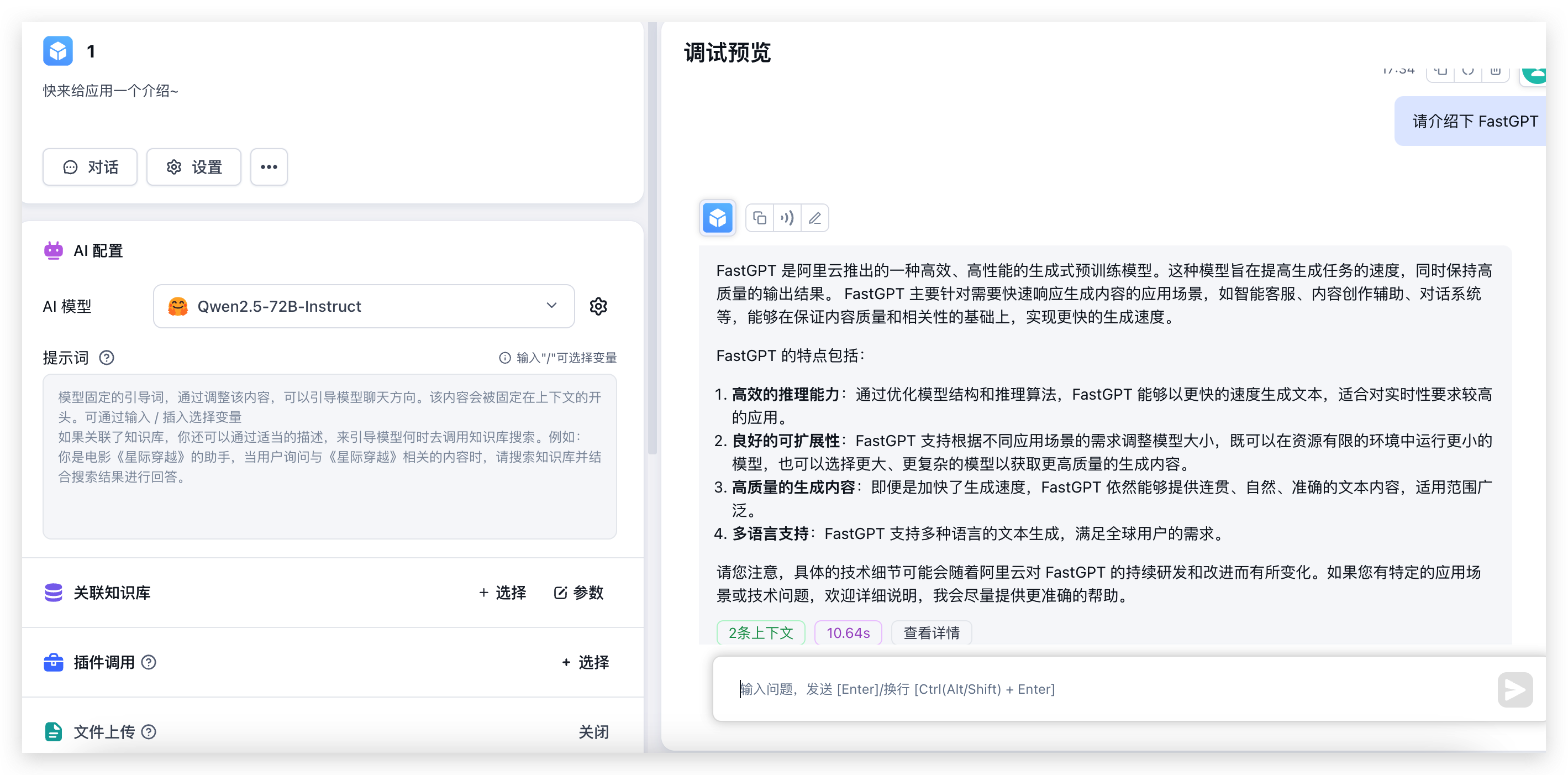 | 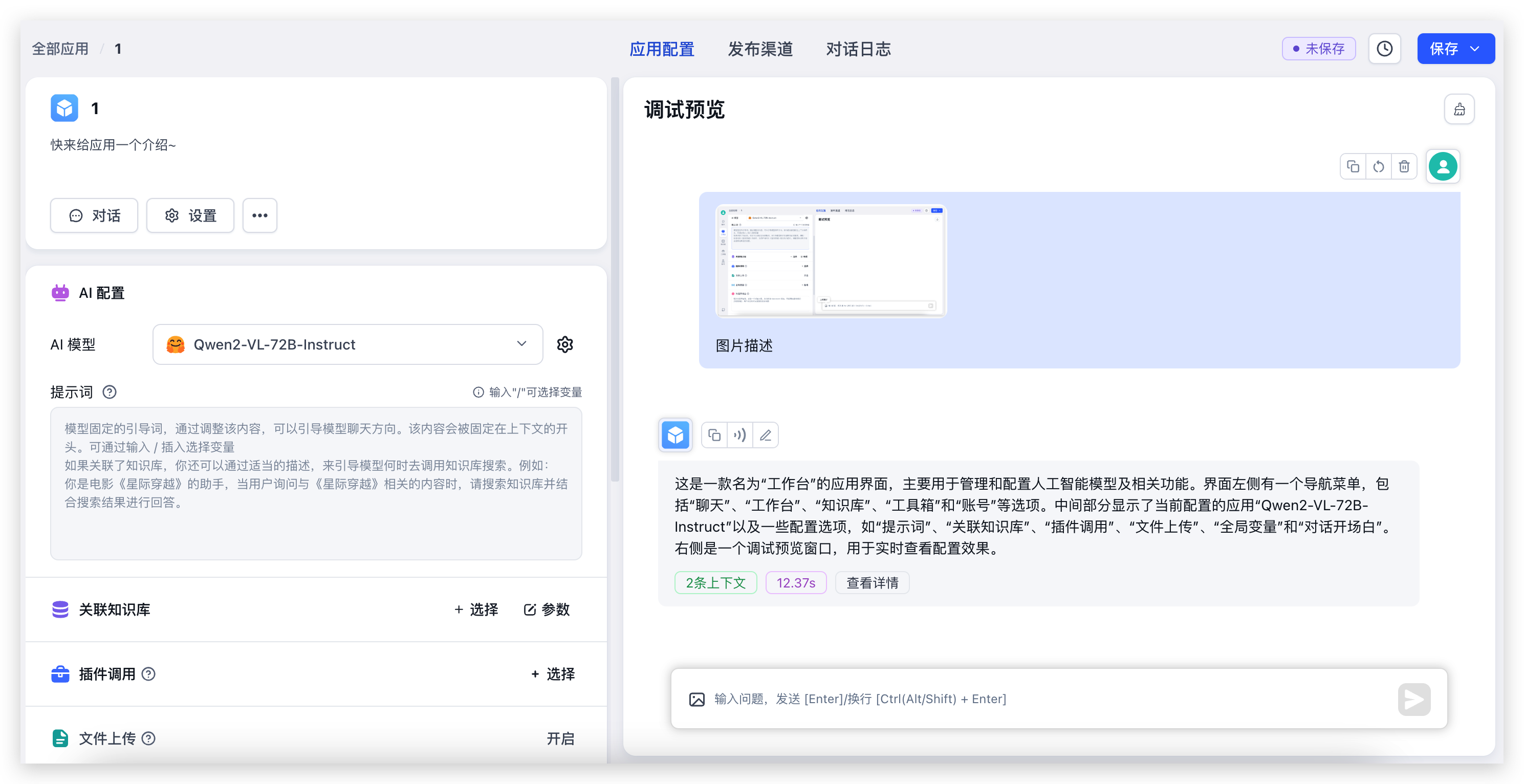 |
可以看到,72B 的模型,性能还是非常快的,这要是本地没几个 4090,不说配置环境,输出怕都要 30s 了。
测试知识库导入和知识库问答
新建一个知识库(由于只配置了一个向量模型,页面上不会展示向量模型选择)
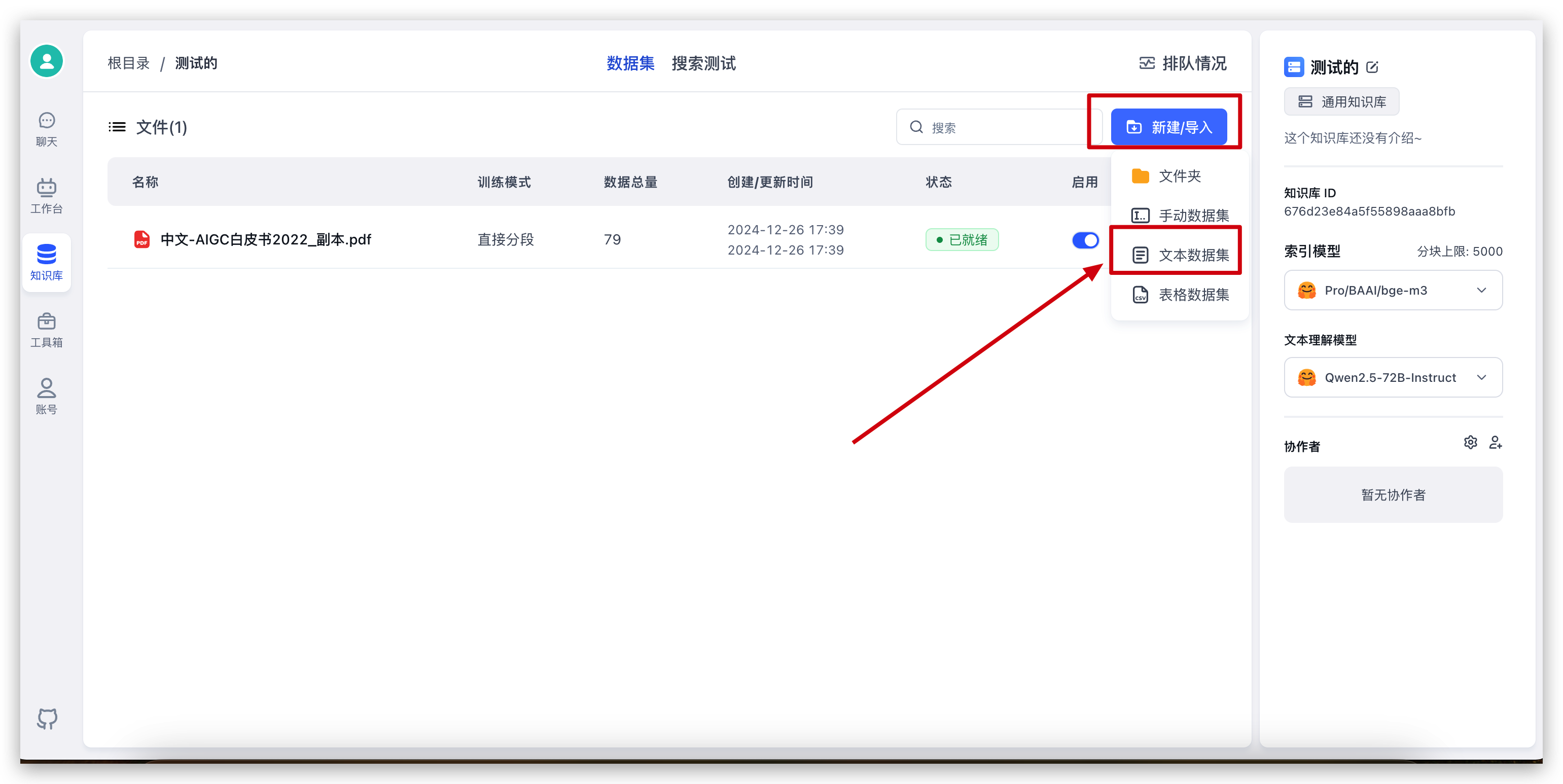 | 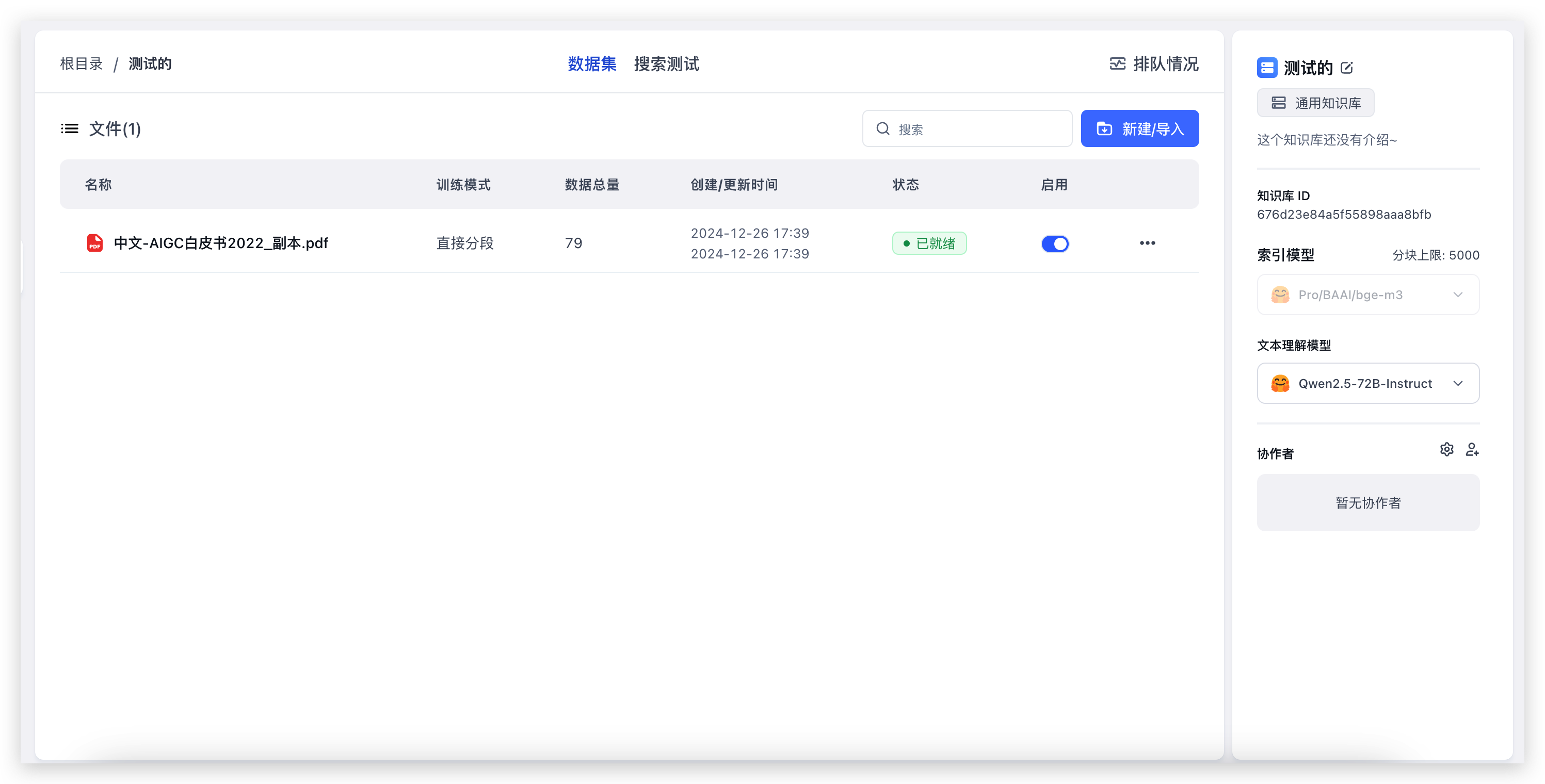 |
导入本地文件,直接选择文件,然后一路下一步即可。79 个索引,大概花了 20s 的时间就完成了。现在我们去测试一下知识库问答。
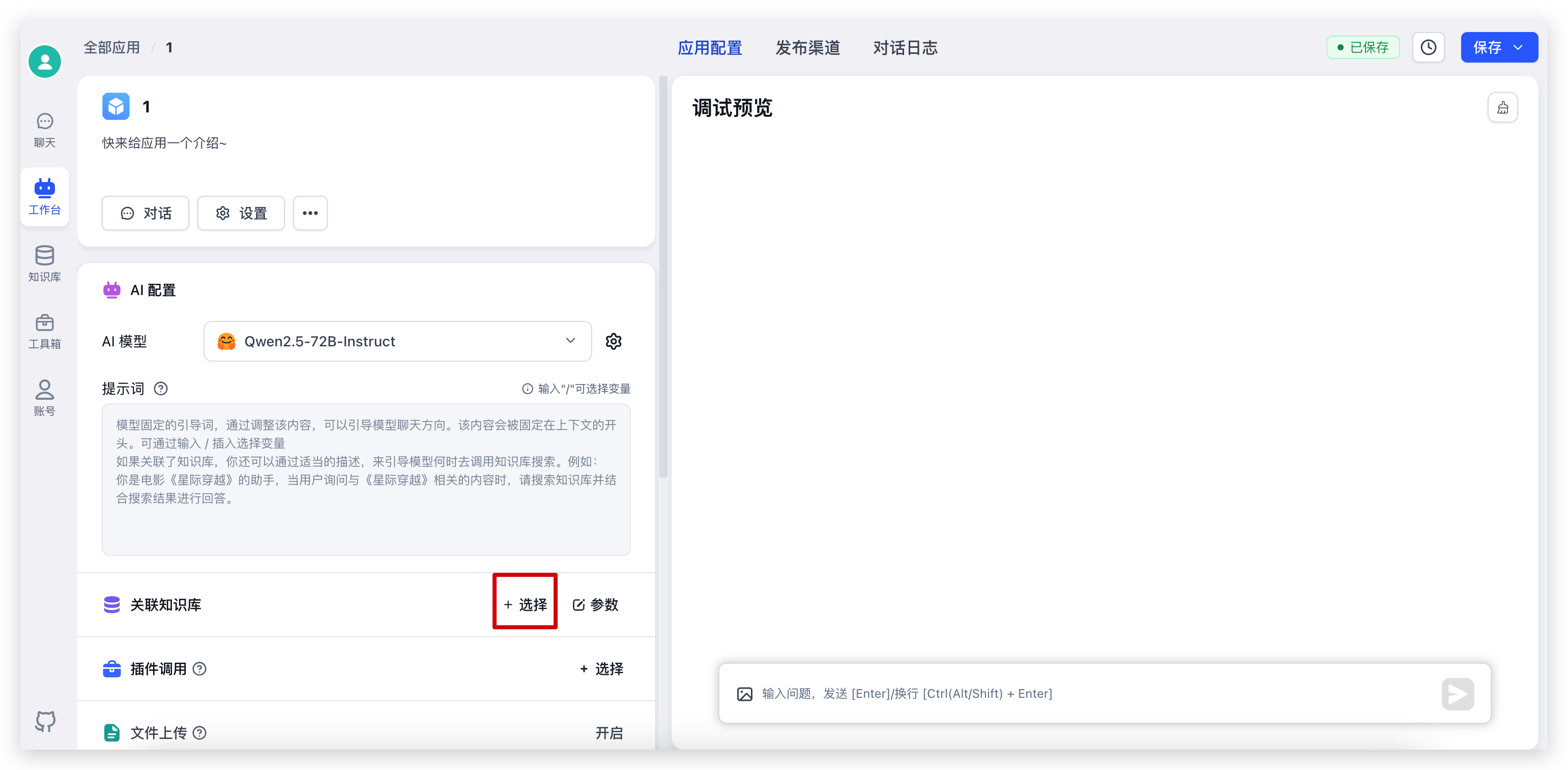
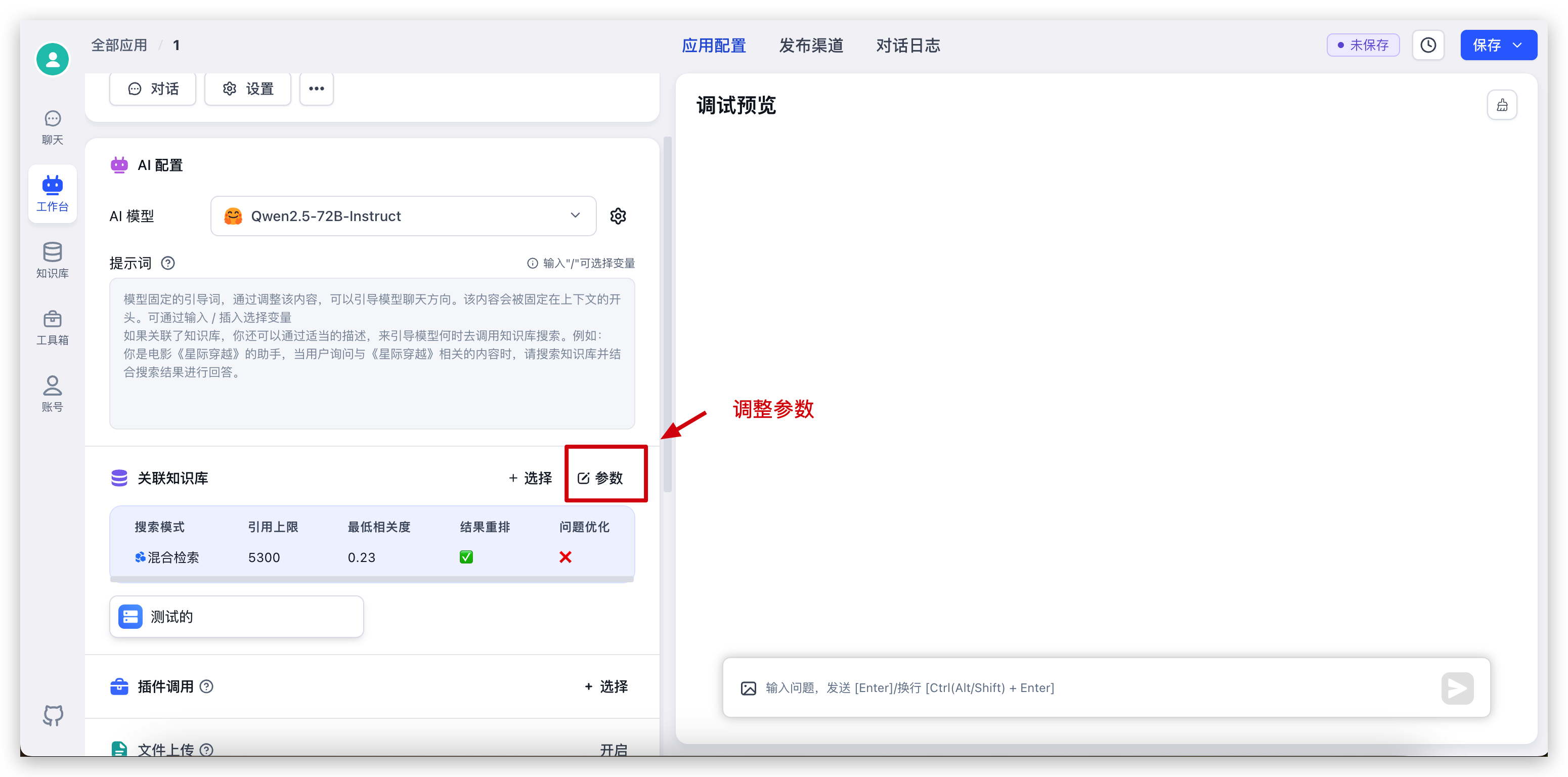
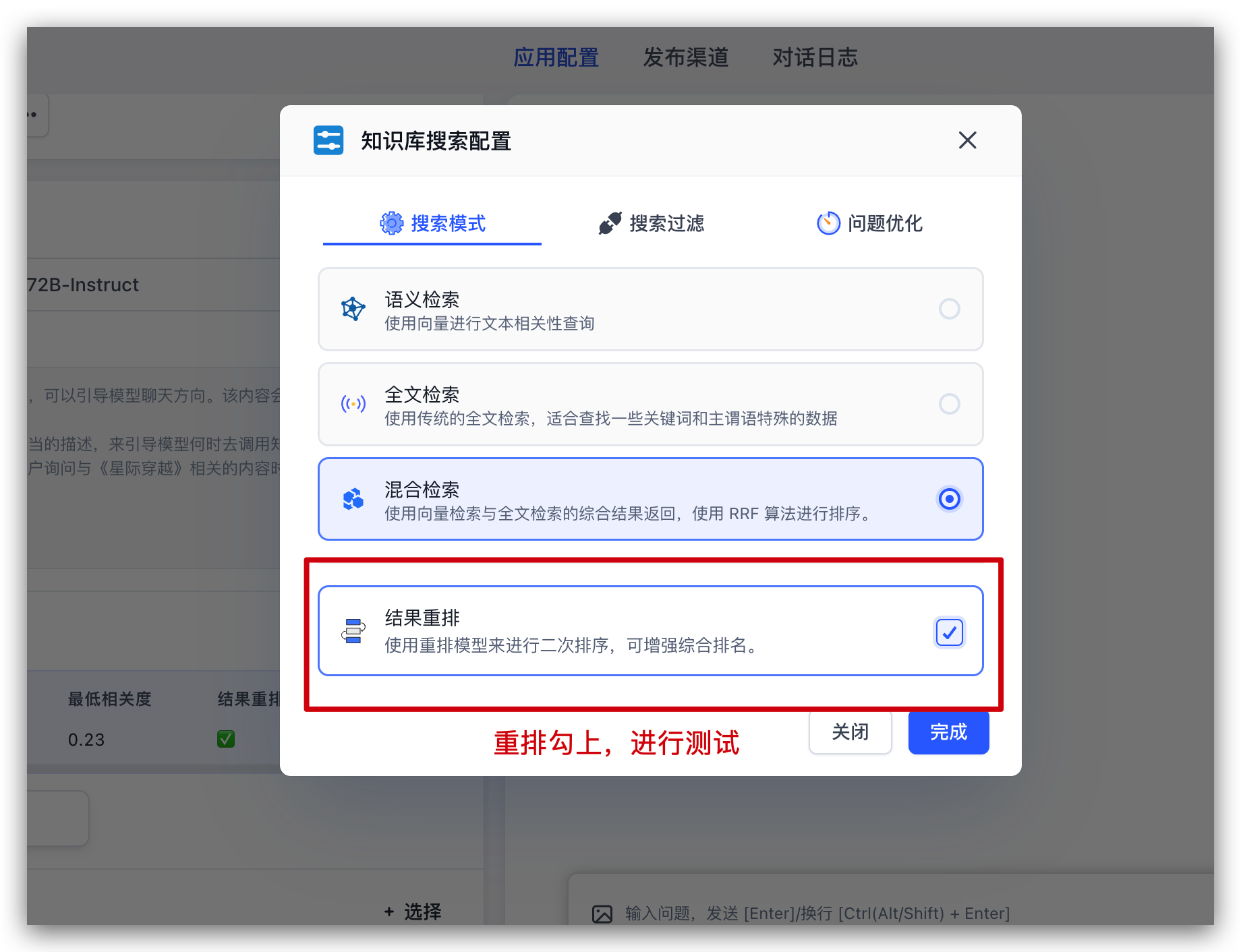
首先回到我们刚创建的应用,选择知识库,调整一下参数后即可开始对话:
 |  |  |
对话完成后,点击底部的引用,可以查看引用详情,同时可以看到具体的检索和重排得分:
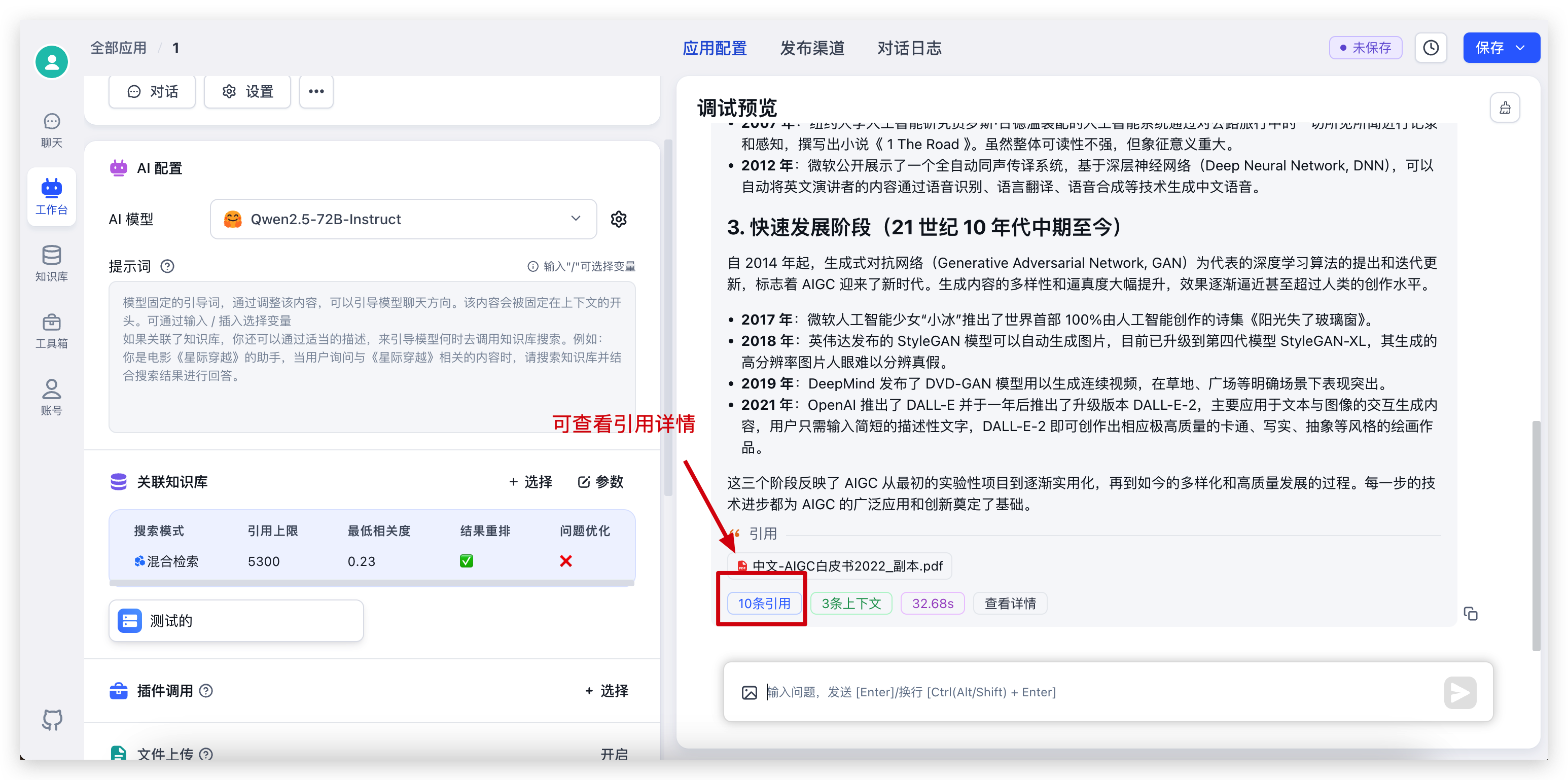 | 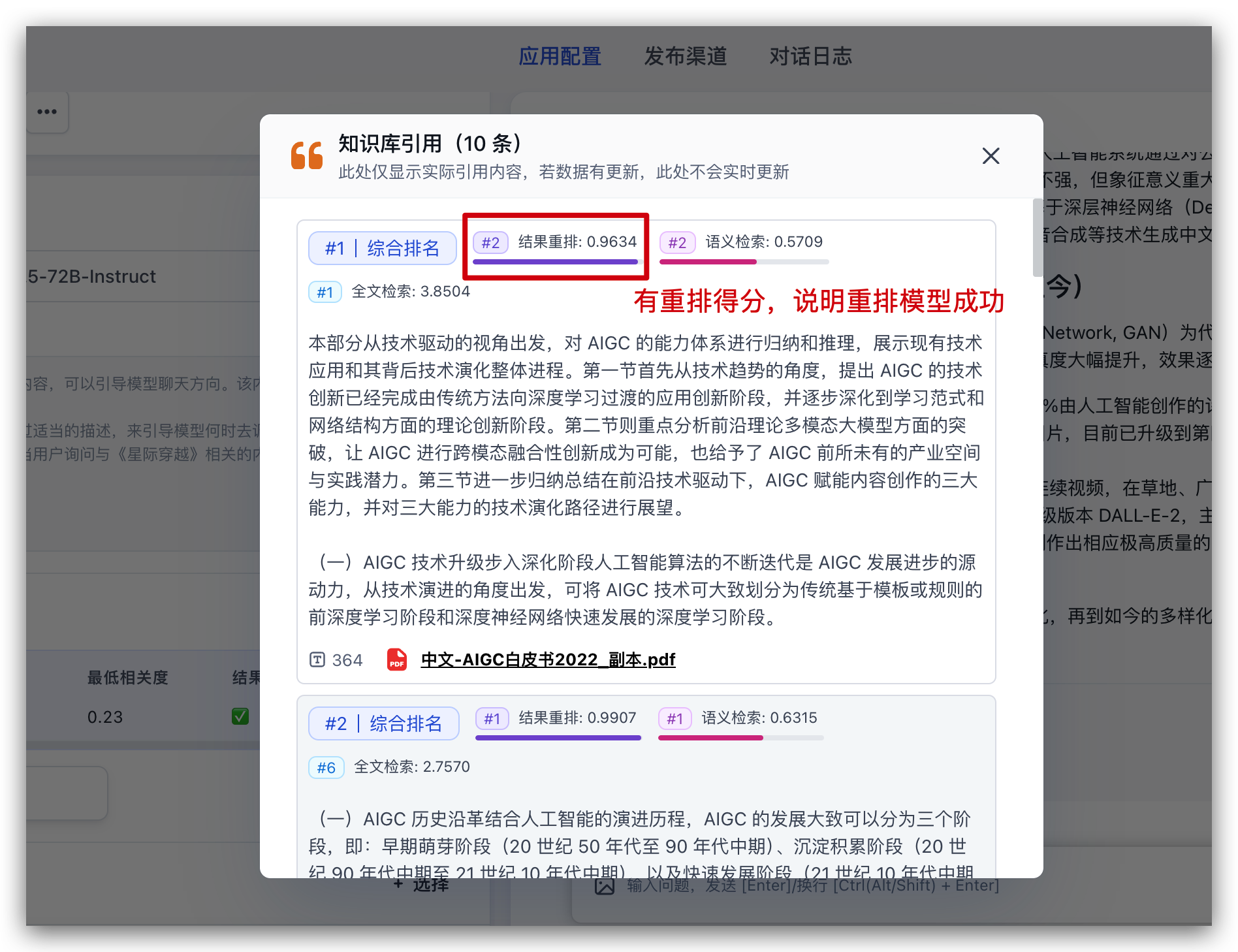 |
测试语音播放
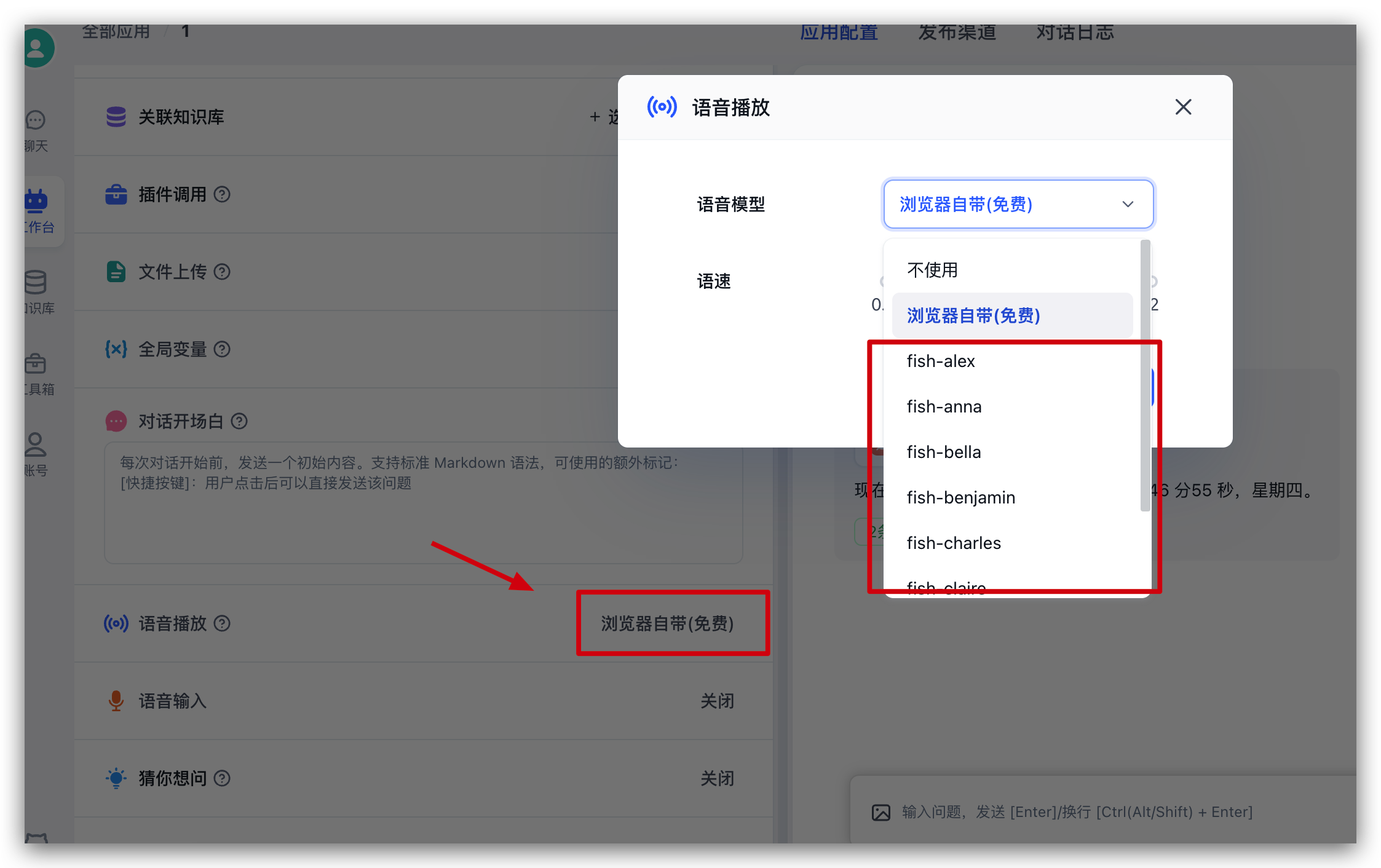
继续在刚刚的应用中,左侧配置中找到语音播放,点击后可以从弹窗中选择语音模型,并进行试听:
测试语言输入
继续在刚刚的应用中,左侧配置中找到语音输入,点击后可以从弹窗中开启语言输入
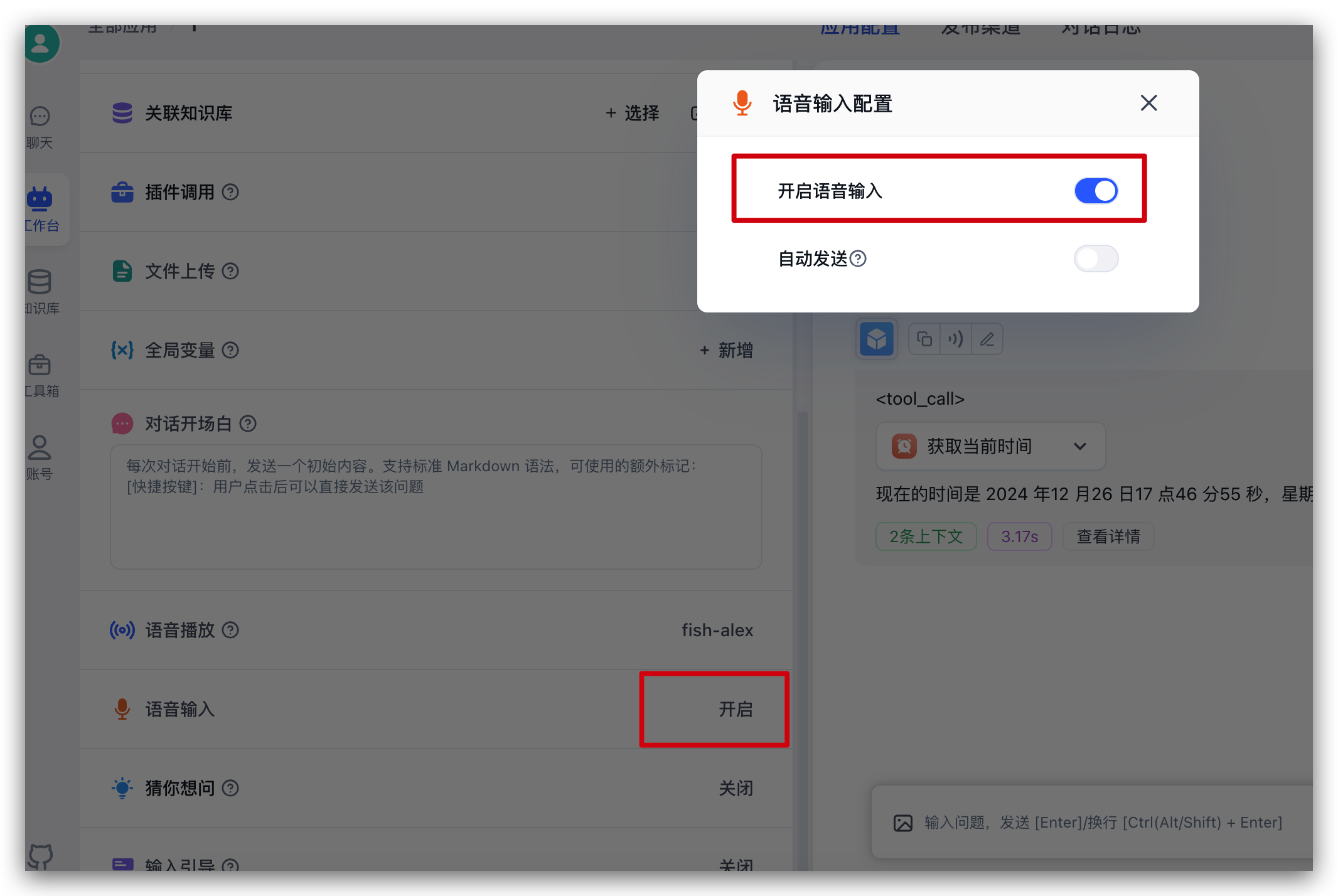
开启后,对话输入框中,会增加一个话筒的图标,点击可进行语音输入:
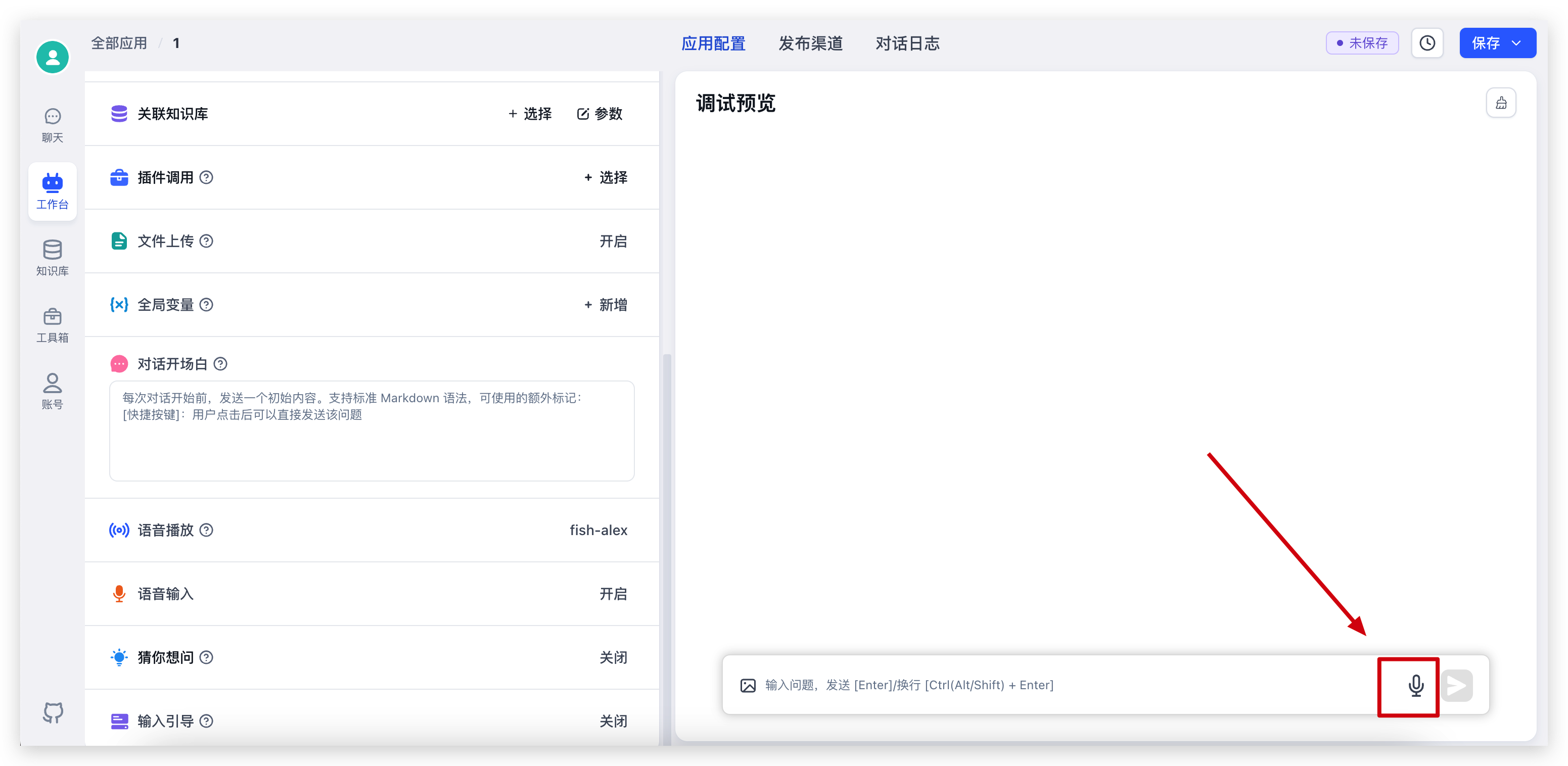 | 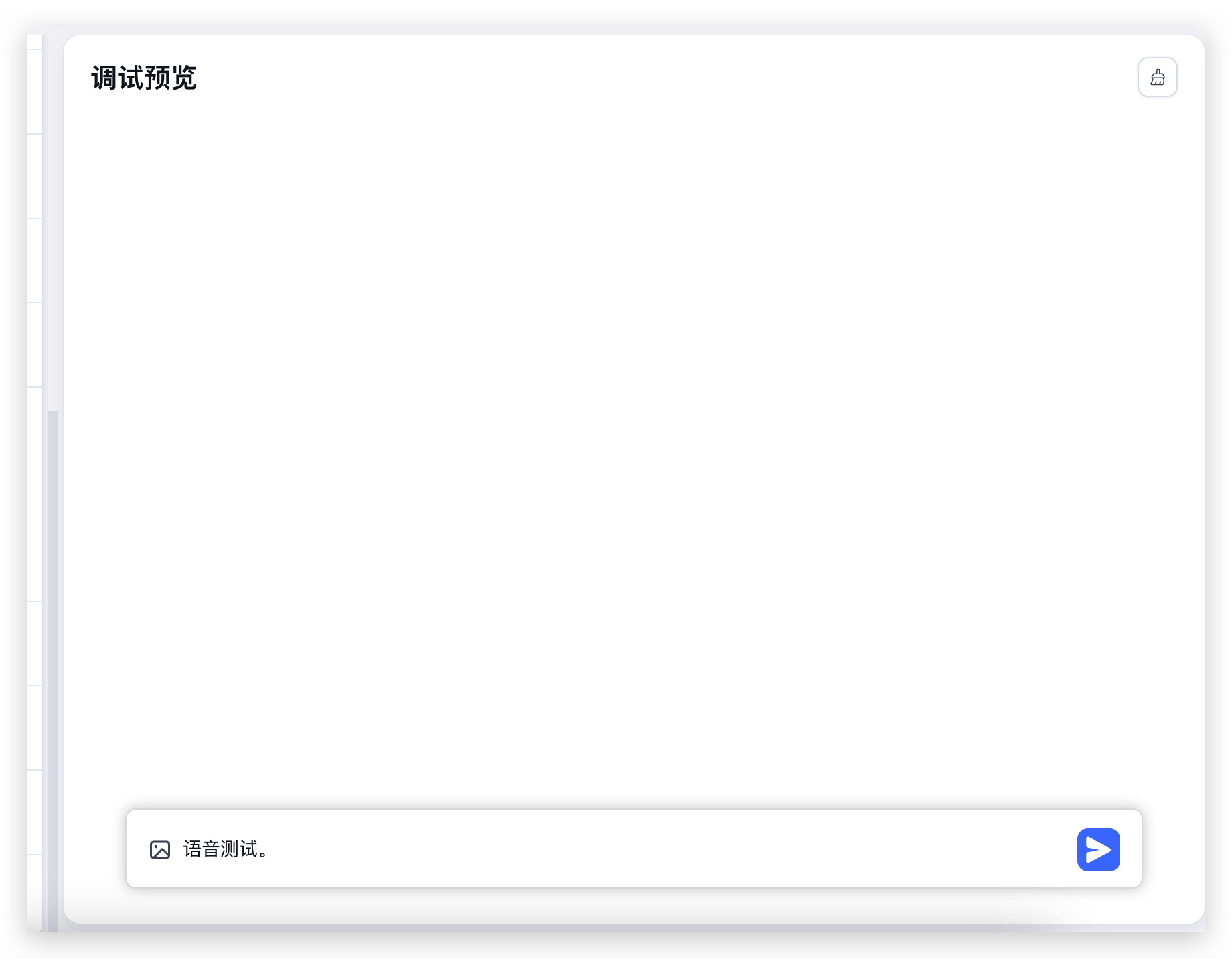 |
总结
如果你想快速的体验开源模型或者快速的使用 FastGPT,不想在不同服务商申请各类 Api Key,那么可以选择 SiliconCloud 的模型先进行快速体验。
如果你决定未来私有化部署模型和 FastGPT,前期可通过 SiliconCloud 进行测试验证,后期再进行硬件采购,减少 POC 时间和成本。