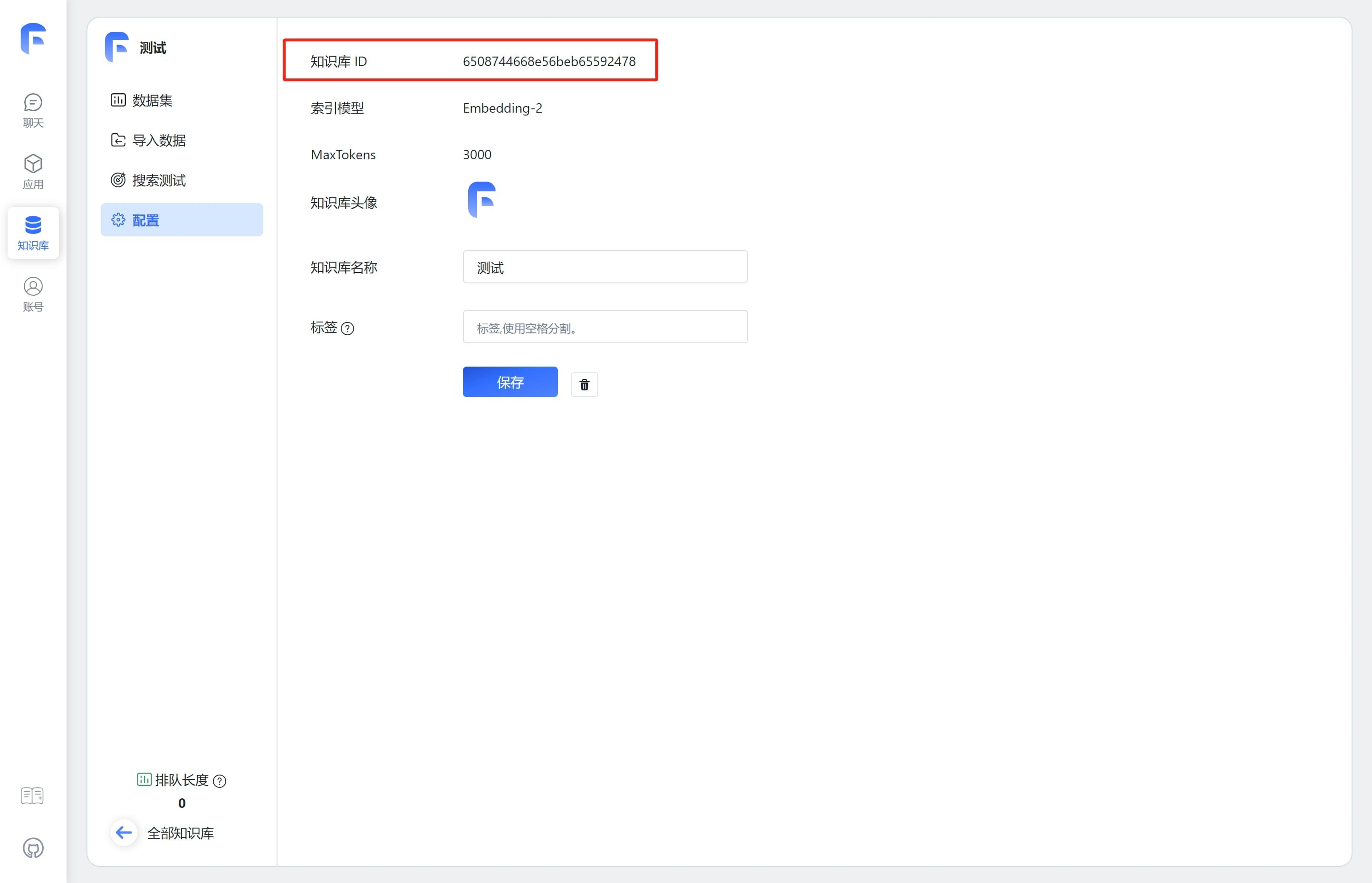
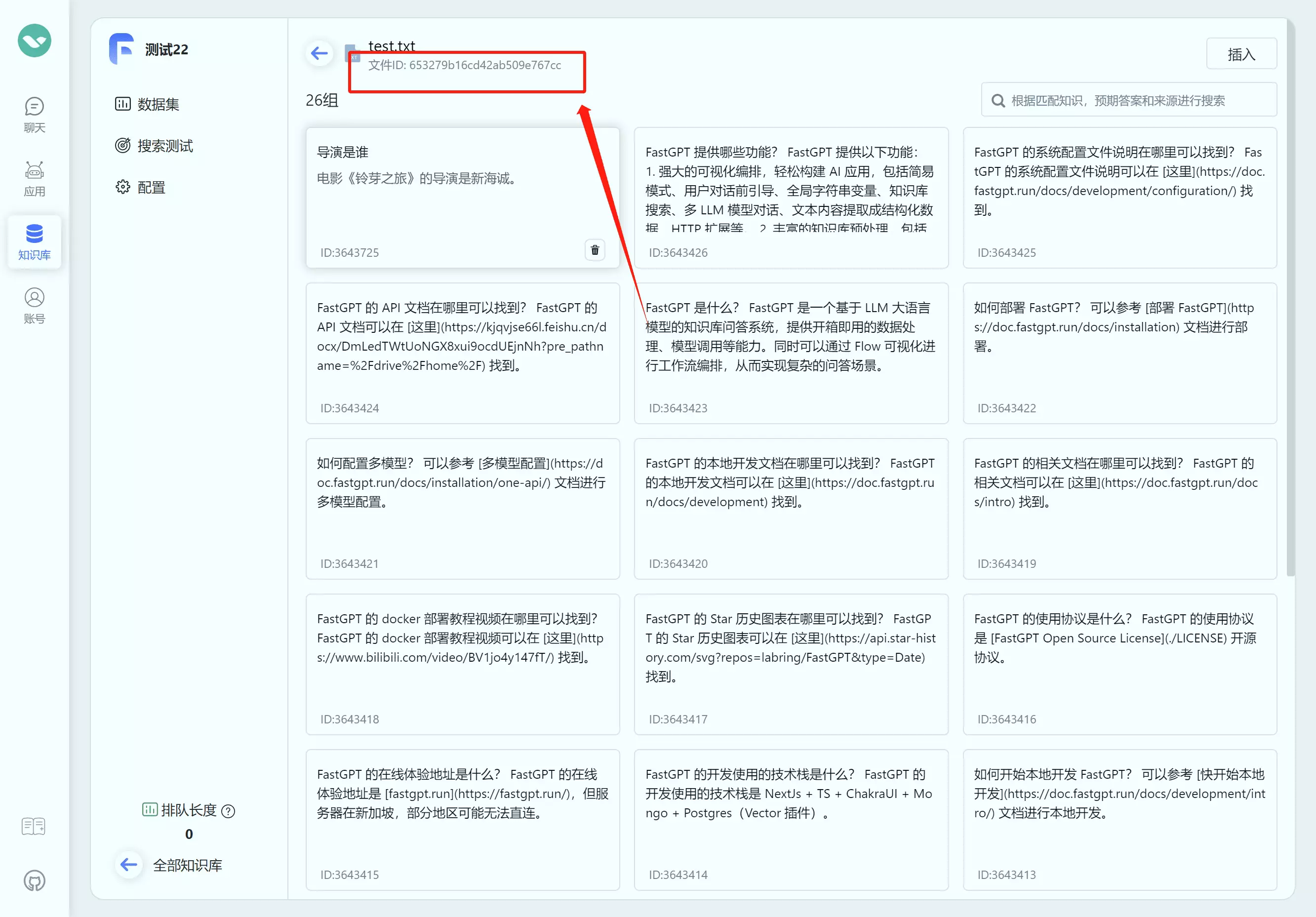
知识库接口
FastGPT OpenAPI 知识库接口
| 如何获取知识库ID(datasetId) | 如何获取文件集合ID(collection_id) |
|---|---|
 |  |
创建训练订单 link
新例子
curl --location --request POST 'http://localhost:3000/api/support/wallet/usage/createTrainingUsage' \
--header 'Authorization: Bearer {{apikey}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"datasetId": "知识库 ID",
"name": "可选,自定义订单名称,例如:文档训练-fastgpt.docx"
}'
data 为 billId,可用于添加知识库数据时进行账单聚合。
{
"code": 200,
"statusText": "",
"message": "",
"data": "65112ab717c32018f4156361"
}
知识库 link
创建一个知识库 link
curl --location --request POST 'http://localhost:3000/api/core/dataset/create' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"parentId": null,
"type": "dataset",
"name":"测试",
"intro":"介绍",
"avatar": "",
"vectorModel": "text-embedding-ada-002",
"agentModel": "gpt-3.5-turbo-16k"
}'
- parentId - 父级ID,用于构建目录结构。通常可以为 null 或者直接不传。
- type -
dataset或者folder,代表普通知识库和文件夹。不传则代表创建普通知识库。 - name - 知识库名(必填)
- intro - 介绍(可选)
- avatar - 头像地址(可选)
- vectorModel - 向量模型(建议传空,用系统默认的)
- agentModel - 文本处理模型(建议传空,用系统默认的)
{
"code": 200,
"statusText": "",
"message": "",
"data": "65abc9bd9d1448617cba5e6c"
}
获取知识库列表 link
curl --location --request POST 'http://localhost:3000/api/core/dataset/list?parentId=' \
--header 'Authorization: Bearer xxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"parentId":""
}'
- parentId - 父级ID,传空字符串或者null,代表获取根目录下的知识库
{
"code": 200,
"statusText": "",
"message": "",
"data": [
{
"_id": "65abc9bd9d1448617cba5e6c",
"parentId": null,
"avatar": "",
"name": "测试",
"intro": "",
"type": "dataset",
"permission": "private",
"canWrite": true,
"isOwner": true,
"vectorModel": {
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 8000,
"weight": 100
}
}
]
}
获取知识库详情 link
curl --location --request GET 'http://localhost:3000/api/core/dataset/detail?id=6593e137231a2be9c5603ba7' \
--header 'Authorization: Bearer {{authorization}}' \
- id: 知识库的ID
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"_id": "6593e137231a2be9c5603ba7",
"parentId": null,
"teamId": "65422be6aa44b7da77729ec8",
"tmbId": "65422be6aa44b7da77729ec9",
"type": "dataset",
"status": "active",
"avatar": "/icon/logo.svg",
"name": "FastGPT test",
"vectorModel": {
"model": "text-embedding-ada-002",
"name": "Embedding-2",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 8000,
"weight": 100
},
"agentModel": {
"model": "gpt-3.5-turbo-16k",
"name": "FastAI-16k",
"maxContext": 16000,
"maxResponse": 16000,
"charsPointsPrice": 0
},
"intro": "",
"permission": "private",
"updateTime": "2024-01-02T10:11:03.084Z",
"canWrite": true,
"isOwner": true
}
}
删除一个知识库 link
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/delete?id=65abc8729d1448617cba5df6' \
--header 'Authorization: Bearer {{authorization}}' \
- id: 知识库的ID
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
集合 link
通用创建参数说明(必看) link
入参
| 参数 | 说明 | 必填 |
|---|---|---|
| datasetId | 知识库ID | ✅ |
| parentId: | 父级ID,不填则默认为根目录 | |
| customPdfParse | PDF增强解析。true: 开启PDF增强解析;不填则默认为false | |
| trainingType | 数据处理方式。chunk: 按文本长度进行分割;qa: 问答对提取 | ✅ |
| chunkTriggerType | 分块条件逻辑。minSize(默认): 大于 n 时分块;maxSize: 小于文件处理模型最大上下文时分块;forceChunk: 强制分块 | |
| chunkTriggerMinSize | chunkTriggerType=minSize 时候填写,原文长度大于该值时候分块(默认 1000) | |
| autoIndexes | 是否自动生成索引(仅商业版支持) | |
| imageIndex | 是否自动生成图片索引(仅商业版支持) | |
| chunkSettingMode | 分块参数模式。auto: 系统默认参数; custom: 手动指定参数 | |
| chunkSplitMode | 分块拆分模式。paragraph:段落优先,再按长度分;size: 按长度拆分; char: 按字符拆分。chunkSettingMode=auto时不生效。 | |
| paragraphChunkDeep | 最大段落深度(默认 5) | |
| chunkSize | 分块大小,默认 1500。chunkSettingMode=auto时不生效。 | |
| indexSize | 索引大小,默认 512,必须小于索引模型最大token。chunkSettingMode=auto时不生效。 | |
| chunkSplitter | 自定义最高优先分割符号,除非超出文件处理最大上下文,否则不会进行进一步拆分。chunkSettingMode=auto时不生效。 | |
| qaPrompt | qa拆分提示词 | |
| tags | 集合标签(字符串数组) | |
| createTime | 文件创建时间(Date / String) |
出参
- collectionId - 新建的集合ID
- insertLen:插入的块数量
创建一个空的集合 link
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"datasetId":"6593e137231a2be9c5603ba7",
"parentId": null,
"name":"测试",
"type":"virtual",
"metadata":{
"test":111
}
}'
- datasetId: 知识库的ID(必填)
- parentId: 父级ID,不填则默认为根目录
- name: 集合名称(必填)
- type:
- folder:文件夹
- virtual:虚拟集合(手动集合)
- metadata: 元数据(暂时没啥用)
data 为集合的 ID。
{
"code": 200,
"statusText": "",
"message": "",
"data": "65abcd009d1448617cba5ee1"
}
创建一个纯文本集合 link
传入一段文字,创建一个集合,会根据传入的文字进行分割。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/text' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"text":"xxxxxxxx",
"datasetId":"6593e137231a2be9c5603ba7",
"parentId": null,
"name":"测试训练",
"trainingType": "qa",
"chunkSettingMode": "auto",
"qaPrompt":"",
"metadata":{}
}'
- text: 原文本
- datasetId: 知识库的ID(必填)
- parentId: 父级ID,不填则默认为根目录
- name: 集合名称(必填)
- metadata: 元数据(暂时没啥用)
data 为集合的 ID。
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"collectionId": "65abcfab9d1448617cba5f0d",
"results": {
"insertLen": 5 // 分割成多少段
}
}
}
创建一个链接集合 link
传入一个网络链接,创建一个集合,会先去对应网页抓取内容,再抓取的文字进行分割。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/link' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"link":"https://doc.tryfastgpt.ai/docs/course/quick-start/",
"datasetId":"6593e137231a2be9c5603ba7",
"parentId": null,
"trainingType": "chunk",
"chunkSettingMode": "auto",
"qaPrompt":"",
"metadata":{
"webPageSelector":".docs-content"
}
}'
- link: 网络链接
- datasetId: 知识库的ID(必填)
- parentId: 父级ID,不填则默认为根目录
- metadata.webPageSelector: 网页选择器,用于指定网页中的哪个元素作为文本(可选)
data 为集合的 ID。
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"collectionId": "65abd0ad9d1448617cba6031",
"results": {
"insertLen": 1
}
}
}
创建一个文件集合 link
传入一个文件,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/localFile' \
--header 'Authorization: Bearer {{authorization}}' \
--form 'file=@"C:\\Users\\user\\Desktop\\fastgpt测试文件\\index.html"' \
--form 'data="{\"datasetId\":\"6593e137231a2be9c5603ba7\",\"parentId\":null,\"trainingType\":\"chunk\",\"chunkSize\":512,\"chunkSplitter\":\"\",\"qaPrompt\":\"\",\"metadata\":{}}"'
需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
- file: 文件
- data: 知识库相关信息(json序列化后传入),参数说明见上方“通用创建参数说明”
由于解析文档是异步操作,此处不会返回插入的数量。
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"collectionId": "65abc044e4704bac793fbd81",
"results": {
"insertLen": 0
}
}
}
创建一个API集合 link
传入一个文件的 id,创建一个集合,会读取文件内容进行分割。目前支持:pdf, docx, md, txt, html, csv。
使用代码上传时,请注意中文 filename 需要进行 encode 处理,否则容易乱码。
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/create/apiCollection' \
--header 'Authorization: Bearer fastgpt-xxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"name": "A Quick Guide to Building a Discord Bot.pdf",
"apiFileId":"A Quick Guide to Building a Discord Bot.pdf",
"datasetId": "674e9e479c3503c385495027",
"parentId": null,
"trainingType": "chunk",
"chunkSize":512,
"chunkSplitter":"",
"qaPrompt":""
}'
需要使用 POST form-data 的格式上传。包含 file 和 data 两个字段。
- name: 集合名,建议就用文件名,必填。
- apiFileId: 文件的ID,必填。
- datasetId: 知识库的ID(必填)
- parentId: 父级ID,不填则默认为根目录
- trainingType:训练模式(必填)
- chunkSize: 每个 chunk 的长度(可选). chunk模式:100~3000; qa模式: 4000~模型最大token(16k模型通常建议不超过10000)
- chunkSplitter: 自定义最高优先分割符号(可选)
- qaPrompt: qa拆分自定义提示词(可选)
data 为集合的 ID。
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"collectionId": "65abc044e4704bac793fbd81",
"results": {
"insertLen": 1
}
}
}
创建一个外部文件库集合(弃用) link
curl --location --request POST 'http://localhost:3000/api/proApi/core/dataset/collection/create/externalFileUrl' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--data-raw '{
"externalFileUrl":"https://image.xxxxx.com/fastgpt-dev/%E6%91%82.pdf",
"externalFileId":"1111",
"createTime": "2024-05-01T00:00:00.000Z",
"filename":"自定义文件名.pdf",
"datasetId":"6642d105a5e9d2b00255b27b",
"parentId": null,
"tags": ["tag1","tag2"],
"trainingType": "chunk",
"chunkSize":512,
"chunkSplitter":"",
"qaPrompt":""
}'
| 参数 | 说明 | 必填 |
|---|---|---|
| externalFileUrl | 文件访问链接(可以是临时链接) | ✅ |
| externalFileId | 外部文件ID | |
| filename | 自定义文件名,需要带后缀 | |
| createTime | 文件创建时间(Date ISO 字符串都 ok) |
data 为集合的 ID。
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"collectionId": "6646fcedfabd823cdc6de746",
"results": {
"insertLen": 1
}
}
}
获取集合列表 link
4.8.19+
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/listV2' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"offset":0,
"pageSize": 10,
"datasetId":"6593e137231a2be9c5603ba7",
"parentId": null,
"searchText":""
}'
4.8.19-(不再维护)
curl --location --request POST 'http://localhost:3000/api/core/dataset/collection/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"pageNum":1,
"pageSize": 10,
"datasetId":"6593e137231a2be9c5603ba7",
"parentId": null,
"searchText":""
}'
- offset: 偏移量
- pageSize: 每页数量,最大30(选填)
- datasetId: 知识库的ID(必填)
- parentId: 父级Id(选填)
- searchText: 模糊搜索文本(选填)
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"list": [
{
"_id": "6593e137231a2be9c5603ba9",
"parentId": null,
"tmbId": "65422be6aa44b7da77729ec9",
"type": "virtual",
"name": "手动录入",
"updateTime": "2099-01-01T00:00:00.000Z",
"dataAmount": 3,
"trainingAmount": 0,
"externalFileId": "1111",
"tags": [
"11",
"测试的"
],
"forbid": false,
"trainingType": "chunk",
"permission": {
"value": 4294967295,
"isOwner": true,
"hasManagePer": true,
"hasWritePer": true,
"hasReadPer": true
}
},
{
"_id": "65abd0ad9d1448617cba6031",
"parentId": null,
"tmbId": "65422be6aa44b7da77729ec9",
"type": "link",
"name": "快速上手 | FastGPT",
"rawLink": "https://doc.tryfastgpt.ai/docs/course/quick-start/",
"updateTime": "2024-01-20T13:54:53.031Z",
"dataAmount": 3,
"trainingAmount": 0,
"externalFileId": "222",
"tags": [
"测试的"
],
"forbid": false,
"trainingType": "chunk",
"permission": {
"value": 4294967295,
"isOwner": true,
"hasManagePer": true,
"hasWritePer": true,
"hasReadPer": true
}
}
],
"total": 93
}
}
获取集合详情 link
curl --location --request GET 'http://localhost:3000/api/core/dataset/collection/detail?id=65abcfab9d1448617cba5f0d' \
--header 'Authorization: Bearer {{authorization}}' \
- id: 集合的ID
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"_id": "65abcfab9d1448617cba5f0d",
"parentId": null,
"teamId": "65422be6aa44b7da77729ec8",
"tmbId": "65422be6aa44b7da77729ec9",
"datasetId": {
"_id": "6593e137231a2be9c5603ba7",
"parentId": null,
"teamId": "65422be6aa44b7da77729ec8",
"tmbId": "65422be6aa44b7da77729ec9",
"type": "dataset",
"status": "active",
"avatar": "/icon/logo.svg",
"name": "FastGPT test",
"vectorModel": "text-embedding-ada-002",
"agentModel": "gpt-3.5-turbo-16k",
"intro": "",
"permission": "private",
"updateTime": "2024-01-02T10:11:03.084Z"
},
"type": "virtual",
"name": "测试训练",
"trainingType": "qa",
"chunkSize": 8000,
"chunkSplitter": "",
"qaPrompt": "11",
"rawTextLength": 40466,
"hashRawText": "47270840614c0cc122b29daaddc09c2a48f0ec6e77093611ab12b69cba7fee12",
"createTime": "2024-01-20T13:50:35.838Z",
"updateTime": "2024-01-20T13:50:35.838Z",
"canWrite": true,
"sourceName": "测试训练"
}
}
修改集合信息 link
通过集合 ID 修改集合信息
curl --location --request PUT 'http://localhost:3000/api/core/dataset/collection/update' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"id":"65abcfab9d1448617cba5f0d",
"parentId": null,
"name": "测2222试",
"tags": ["tag1", "tag2"],
"forbid": false,
"createTime": "2024-01-01T00:00:00.000Z"
}'
通过外部文件 ID 修改集合信息, 只需要把 id 换成 datasetId 和 externalFileId。
curl --location --request PUT 'http://localhost:3000/api/core/dataset/collection/update' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"datasetId":"6593e137231a2be9c5603ba7",
"externalFileId":"1111",
"parentId": null,
"name": "测2222试",
"tags": ["tag1", "tag2"],
"forbid": false,
"createTime": "2024-01-01T00:00:00.000Z"
}'
- id: 集合的ID
- parentId: 修改父级ID(可选)
- name: 修改集合名称(可选)
- tags: 修改集合标签(可选)
- forbid: 修改集合禁用状态(可选)
- createTime: 修改集合创建时间(可选)
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
删除一个集合 link
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/collection/delete?id=65aa2a64e6cb9b8ccdc00de8' \
--header 'Authorization: Bearer {{authorization}}' \
- id: 集合的ID
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
数据 link
数据的结构 link
Data结构
| 字段 | 类型 | 说明 | 必填 |
|---|---|---|---|
| teamId | String | 团队ID | ✅ |
| tmbId | String | 成员ID | ✅ |
| datasetId | String | 知识库ID | ✅ |
| collectionId | String | 集合ID | ✅ |
| q | String | 主要数据 | ✅ |
| a | String | 辅助数据 | ✖ |
| fullTextToken | String | 分词 | ✖ |
| indexes | Index[] | 向量索引 | ✅ |
| updateTime | Date | 更新时间 | ✅ |
| chunkIndex | Number | 分块下表 | ✖ |
Index结构
每组数据的自定义索引最多5个
| 字段 | 类型 | 说明 | 必填 |
|---|---|---|---|
| type | String | 可选索引类型:default-默认索引; custom-自定义索引; summary-总结索引; question-问题索引; image-图片索引 | |
| dataId | String | 关联的向量ID,变更数据时候传入该 ID,会进行差量更新,而不是全量更新 | |
| text | String | 文本内容 | ✅ |
type 不填则默认为 custom 索引,还会基于 q/a 组成一个默认索引。如果传入了默认索引,则不会额外创建。
为集合批量添加添加数据 link
注意,每次最多推送 200 组数据。
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/data/pushData' \
--header 'Authorization: Bearer apikey' \
--header 'Content-Type: application/json' \
--data-raw '{
"collectionId": "64663f451ba1676dbdef0499",
"trainingType": "chunk",
"prompt": "可选。qa 拆分引导词,chunk 模式下忽略",
"billId": "可选。如果有这个值,本次的数据会被聚合到一个订单中,这个值可以重复使用。可以参考 [创建训练订单] 获取该值。",
"data": [
{
"q": "你是谁?",
"a": "我是FastGPT助手"
},
{
"q": "你会什么?",
"a": "我什么都会",
"indexes": [
{
"text":"自定义索引1"
},
{
"text":"自定义索引2"
}
]
}
]
}'
- collectionId: 集合ID(必填)
- trainingType:训练模式(必填)
- prompt: 自定义 QA 拆分提示词,需严格按照模板,建议不要传入。(选填)
- data:(具体数据)
- q: 主要数据(必填)
- a: 辅助数据(选填)
- indexes: 自定义索引(选填)。可以不传或者传空数组,默认都会使用q和a组成一个索引。
{
"code": 200,
"statusText": "",
"data": {
"insertLen": 1, // 最终插入成功的数量
"overToken": [], // 超出 token 的
"repeat": [], // 重复的数量
"error": [] // 其他错误
}
}
{{theme}} 里的内容可以换成数据的主题。默认为:它们可能包含多个主题内容
我会给你一段文本,{{theme}},学习它们,并整理学习成果,要求为:
1. 提出最多 25 个问题。
2. 给出每个问题的答案。
3. 答案要详细完整,答案可以包含普通文字、链接、代码、表格、公示、媒体链接等 markdown 元素。
4. 按格式返回多个问题和答案:
Q1: 问题。
A1: 答案。
Q2:
A2:
……
我的文本:"""{{text}}"""
获取集合的数据列表 link
4.8.11+
curl --location --request POST 'http://localhost:3000/api/core/dataset/data/v2/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"offset": 0,
"pageSize": 10,
"collectionId":"65abd4ac9d1448617cba6171",
"searchText":""
}'
4.6.7-(即将弃用)
curl --location --request POST 'http://localhost:3000/api/core/dataset/data/list' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"pageNum":1,
"pageSize": 10,
"collectionId":"65abd4ac9d1448617cba6171",
"searchText":""
}'
- offset: 偏移量(选填)
- pageSize: 每页数量,最大30(选填)
- collectionId: 集合的ID(必填)
- searchText: 模糊搜索词(选填)
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"list": [
{
"_id": "65abd4b29d1448617cba61db",
"datasetId": "65abc9bd9d1448617cba5e6c",
"collectionId": "65abd4ac9d1448617cba6171",
"q": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
"a": "",
"chunkIndex": 0
},
{
"_id": "65abd4b39d1448617cba624d",
"datasetId": "65abc9bd9d1448617cba5e6c",
"collectionId": "65abd4ac9d1448617cba6171",
"q": "本白皮书重点从 AIGC 技术、应用和治理等维度进行了阐述。在技术层面,梳理提出了 AIGC 技术体系,既涵盖了对现实世界各种内容的数字化呈现和增强,也包括了基于人工智能的自主内容创作。在应用层面,重点分析了 AIGC 在传媒、电商、影视等行业和场景的应用情况,探讨了以虚拟数字人、写作机器人等为代表的新业态和新应用。在治理层面,从政策监管、技术能力、企业应用等视角,分析了AIGC 所暴露出的版权纠纷、虚假信息传播等各种问题。最后,从政府、行业、企业、社会等层面,给出了 AIGC 发展和治理建议。由于人工智能仍处于飞速发展阶段,我们对 AIGC 的认识还有待进一步深化,白皮书中存在不足之处,敬请大家批评指正。目 录一、 人工智能生成内容的发展历程与概念.............................................................. 1(一)AIGC 历史沿革 .......................................................................................... 1(二)AIGC 的概念与内涵 .................................................................................. 4二、人工智能生成内容的技术体系及其演进方向.................................................... 7(一)AIGC 技术升级步入深化阶段 .................................................................. 7(二)AIGC 大模型架构潜力凸显 .................................................................... 10(三)AIGC 技术演化出三大前沿能力 ............................................................ 18三、人工智能生成内容的应用场景.......................................................................... 26(一)AIGC+传媒:人机协同生产,",
"a": "",
"chunkIndex": 1
}
],
"total": 63
}
}
获取单条数据详情 link
curl --location --request GET 'http://localhost:3000/api/core/dataset/data/detail?id=65abd4b29d1448617cba61db' \
--header 'Authorization: Bearer {{authorization}}' \
- id: 数据的id
{
"code": 200,
"statusText": "",
"message": "",
"data": {
"id": "65abd4b29d1448617cba61db",
"q": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
"a": "",
"chunkIndex": 0,
"indexes": [
{
"type": "default",
"dataId": "3720083",
"text": "N o . 2 0 2 2 1 2中 国 信 息 通 信 研 究 院京东探索研究院2022年 9月人工智能生成内容(AIGC)白皮书(2022 年)版权声明本白皮书版权属于中国信息通信研究院和京东探索研究院,并受法律保护。转载、摘编或利用其它方式使用本白皮书文字或者观点的,应注明“来源:中国信息通信研究院和京东探索研究院”。违反上述声明者,编者将追究其相关法律责任。前 言习近平总书记曾指出,“数字技术正以新理念、新业态、新模式全面融入人类经济、政治、文化、社会、生态文明建设各领域和全过程”。在当前数字世界和物理世界加速融合的大背景下,人工智能生成内容(Artificial Intelligence Generated Content,简称 AIGC)正在悄然引导着一场深刻的变革,重塑甚至颠覆数字内容的生产方式和消费模式,将极大地丰富人们的数字生活,是未来全面迈向数字文明新时代不可或缺的支撑力量。",
"_id": "65abd4b29d1448617cba61dc"
}
],
"datasetId": "65abc9bd9d1448617cba5e6c",
"collectionId": "65abd4ac9d1448617cba6171",
"sourceName": "中文-AIGC白皮书2022.pdf",
"sourceId": "65abd4ac9d1448617cba6166",
"isOwner": true,
"canWrite": true
}
}
修改单条数据 link
curl --location --request PUT 'http://localhost:3000/api/core/dataset/data/update' \
--header 'Authorization: Bearer {{authorization}}' \
--header 'Content-Type: application/json' \
--data-raw '{
"dataId":"65abd4b29d1448617cba61db",
"q":"测试111",
"a":"sss",
"indexes":[
{
"dataId": "xxxx",
"type": "default",
"text": "默认索引"
},
{
"dataId": "xxx",
"type": "custom",
"text": "旧的自定义索引1"
},
{
"type":"custom",
"text":"新增的自定义索引"
}
]
}'
- dataId: 数据的id
- q: 主要数据(选填)
- a: 辅助数据(选填)
- indexes: 自定义索引(选填),类型参考
为集合批量添加添加数据。如果创建时候有自定义索引,
{
"code": 200,
"statusText": "",
"message": "",
"data": null
}
删除单条数据 link
curl --location --request DELETE 'http://localhost:3000/api/core/dataset/data/delete?id=65abd4b39d1448617cba624d' \
--header 'Authorization: Bearer {{authorization}}' \
- id: 数据的id
{
"code": 200,
"statusText": "",
"message": "",
"data": "success"
}
搜索测试 link
curl --location --request POST 'https://api.fastgpt.in/api/core/dataset/searchTest' \
--header 'Authorization: Bearer fastgpt-xxxxx' \
--header 'Content-Type: application/json' \
--data-raw '{
"datasetId": "知识库的ID",
"text": "导演是谁",
"limit": 5000,
"similarity": 0,
"searchMode": "embedding",
"usingReRank": false,
"datasetSearchUsingExtensionQuery": true,
"datasetSearchExtensionModel": "gpt-4o-mini",
"datasetSearchExtensionBg": ""
}'
- datasetId - 知识库ID
- text - 需要测试的文本
- limit - 最大 tokens 数量
- similarity - 最低相关度(0~1,可选)
- searchMode - 搜索模式:embedding | fullTextRecall | mixedRecall
- usingReRank - 使用重排
- datasetSearchUsingExtensionQuery - 使用问题优化
- datasetSearchExtensionModel - 问题优化模型
- datasetSearchExtensionBg - 问题优化背景描述
返回 top k 结果, limit 为最大 Tokens 数量,最多 20000 tokens。
{
"code": 200,
"statusText": "",
"data": [
{
"id": "65599c54a5c814fb803363cb",
"q": "你是谁",
"a": "我是FastGPT助手",
"datasetId": "6554684f7f9ed18a39a4d15c",
"collectionId": "6556cd795e4b663e770bb66d",
"sourceName": "GBT 15104-2021 装饰单板贴面人造板.pdf",
"sourceId": "6556cd775e4b663e770bb65c",
"score": 0.8050316572189331
},
......
]
}