分享链接身份鉴权
FastGPT 分享链接身份鉴权
介绍
在 FastGPT V4.6.4 中,我们修改了分享链接的数据读取方式,为每个用户生成一个 localId,用于标识用户,从云端拉取对话记录。但是这种方式仅能保障用户在同一设备同一浏览器中使用,如果切换设备或者清空浏览器缓存则会丢失这些记录。这种方式存在一定的风险,因此我们仅允许用户拉取近30天的20条记录。
分享链接身份鉴权设计的目的在于,将 FastGPT 的对话框快速、安全的接入到你现有的系统中,仅需 2 个接口即可实现。该功能目前只在商业版中提供。
使用说明
免登录链接配置中,你可以选择填写身份验证栏。这是一个POST请求的根地址。在填写该地址后,分享链接的初始化、开始对话以及对话结束都会向该地址的特定接口发送一条请求。下面以host来表示凭身份验证根地址。服务器接口仅需返回是否校验成功即可,不需要返回其他数据,格式如下:
接口统一响应格式
{
"success": true,
"message": "错误提示",
"msg": "同message, 错误提示",
"data": {
"uid": "用户唯一凭证"
}
}
FastGPT 将会判断success是否为true决定是允许用户继续操作。message与msg是等同的,你可以选择返回其中一个,当success不为true时,将会提示这个错误。
uid是用户的唯一凭证,将会用于拉取对话记录以及保存对话记录。可参考下方实践案例。
触发流程

配置教程
1. 配置身份校验地址
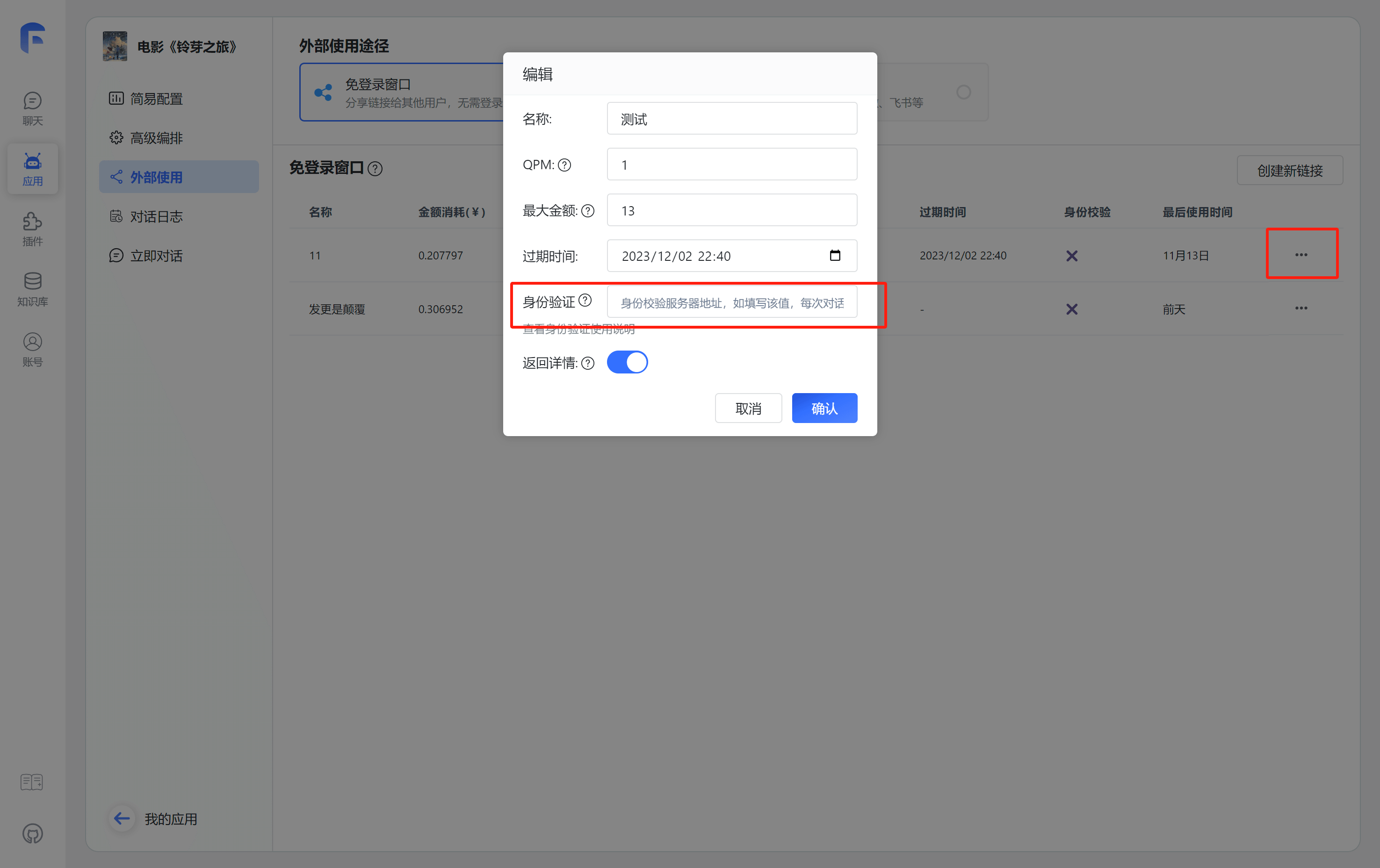
配置校验地址后,在每次分享链接使用时,都会向对应的地址发起校验和上报请求。
这里仅需配置根地址,无需具体到完整请求路径。
2. 分享链接中增加额外 query
在分享链接的地址中,增加一个额外的参数: authToken。例如:
原始的链接:https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192
完整链接: https://share.tryfastgpt.ai/chat/share?shareId=648aaf5ae121349a16d62192&authToken=userid12345
这个authToken通常是你系统生成的用户唯一凭证(Token之类的)。FastGPT 会在鉴权接口的body中携带 token={{authToken}} 的参数。
3. 编写聊天初始化校验接口
4. 编写对话前校验接口
5. 编写对话结果上报接口(可选)
该接口无规定返回值。
响应值与chat 接口格式相同,仅多了一个token。
重点关注:totalPoints(总消耗AI积分),token(Token消耗总数)
curl --location --request POST '{{host}}/shareAuth/finish' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "{{authToken}}",
"responseData": [
{
"moduleName": "core.module.template.Dataset search",
"moduleType": "datasetSearchNode",
"totalPoints": 1.5278,
"query": "导演是谁\n《铃芽之旅》的导演是谁?\n这部电影的导演是谁?\n谁是《铃芽之旅》的导演?",
"model": "Embedding-2(旧版,不推荐使用)",
"tokens": 1524,
"similarity": 0.83,
"limit": 400,
"searchMode": "embedding",
"searchUsingReRank": false,
"extensionModel": "FastAI-4k",
"extensionResult": "《铃芽之旅》的导演是谁?\n这部电影的导演是谁?\n谁是《铃芽之旅》的导演?",
"runningTime": 2.15
},
{
"moduleName": "AI 对话",
"moduleType": "chatNode",
"totalPoints": 0.593,
"model": "FastAI-4k",
"tokens": 593,
"query": "导演是谁",
"maxToken": 2000,
"quoteList": [
{
"id": "65bb346a53698398479a8854",
"q": "导演是谁?",
"a": "电影《铃芽之旅》的导演是新海诚。",
"chunkIndex": 0,
"datasetId": "65af9b947916ae0e47c834d2",
"collectionId": "65bb345c53698398479a868f",
"sourceName": "dataset - 2024-01-23T151114.198.csv",
"sourceId": "65bb345b53698398479a868d",
"score": [
{
"type": "embedding",
"value": 0.9377183318138123,
"index": 0
},
{
"type": "rrf",
"value": 0.06557377049180328,
"index": 0
}
]
}
],
"historyPreview": [
{
"obj": "Human",
"value": "使用 <Data></Data> 标记中的内容作为本次对话的参考:\n\n<Data>\n导演是谁?\n电影《铃芽之旅》的导演是新海诚。\n------\n电影《铃芽之旅》的编剧是谁?22\n新海诚是本片的编剧。\n------\n电影《铃芽之旅》的女主角是谁?\n电影的女主角是铃芽。\n------\n电影《铃芽之旅》的制作团队中有哪位著名人士?2\n川村元气是本片的制作团队成员之一。\n------\n你是谁?\n我是电影《铃芽之旅》助手\n------\n电影《铃芽之旅》男主角是谁?\n电影《铃芽之旅》男主角是宗像草太,由松村北斗配音。\n------\n电影《铃芽之旅》的作者新海诚写了一本小说,叫什么名字?\n小说名字叫《铃芽之旅》。\n------\n电影《铃芽之旅》的女主角是谁?\n电影《铃芽之旅》的女主角是岩户铃芽,由原菜乃华配音。\n------\n电影《铃芽之旅》的故事背景是什么?\n日本\n------\n谁担任电影《铃芽之旅》中岩户环的配音?\n深津绘里担任电影《铃芽之旅》中岩户环的配音。\n</Data>\n\n回答要求:\n- 如果你不清楚答案,你需要澄清。\n- 避免提及你是从 <Data></Data> 获取的知识。\n- 保持答案与 <Data></Data> 中描述的一致。\n- 使用 Markdown 语法优化回答格式。\n- 使用与问题相同的语言回答。\n\n问题:\"\"\"导演是谁\"\"\""
},
{
"obj": "AI",
"value": "电影《铃芽之旅》的导演是新海诚。"
}
],
"contextTotalLen": 2,
"runningTime": 1.32
}
]
}'
responseData 完整字段说明:
type ResponseType = {
moduleType: FlowNodeTypeEnum; // 模块类型
moduleName: string; // 模块名
moduleLogo?: string; // logo
runningTime?: number; // 运行时间
query?: string; // 用户问题/检索词
textOutput?: string; // 文本输出
tokens?: number; // 上下文总Tokens
model?: string; // 使用到的模型
contextTotalLen?: number; // 上下文总长度
totalPoints?: number; // 总消耗AI积分
temperature?: number; // 温度
maxToken?: number; // 模型的最大token
quoteList?: SearchDataResponseItemType[]; // 引用列表
historyPreview?: ChatItemType[]; // 上下文预览(历史记录会被裁剪)
similarity?: number; // 最低相关度
limit?: number; // 引用上限token
searchMode?: `${DatasetSearchModeEnum}`; // 搜索模式
searchUsingReRank?: boolean; // 是否使用rerank
extensionModel?: string; // 问题扩展模型
extensionResult?: string; // 问题扩展结果
extensionTokens?: number; // 问题扩展总字符长度
cqList?: ClassifyQuestionAgentItemType[]; // 分类问题列表
cqResult?: string; // 分类问题结果
extractDescription?: string; // 内容提取描述
extractResult?: Record<string, any>; // 内容提取结果
params?: Record<string, any>; // HTTP模块params
body?: Record<string, any>; // HTTP模块body
headers?: Record<string, any>; // HTTP模块headers
httpResult?: Record<string, any>; // HTTP模块结果
pluginOutput?: Record<string, any>; // 插件输出
pluginDetail?: ChatHistoryItemResType[]; // 插件详情
isElseResult?: boolean; // 判断器结果
}
实践案例
我们以Laf作为服务器为例,简单展示这 3 个接口的使用方式。
1. 创建3个Laf接口
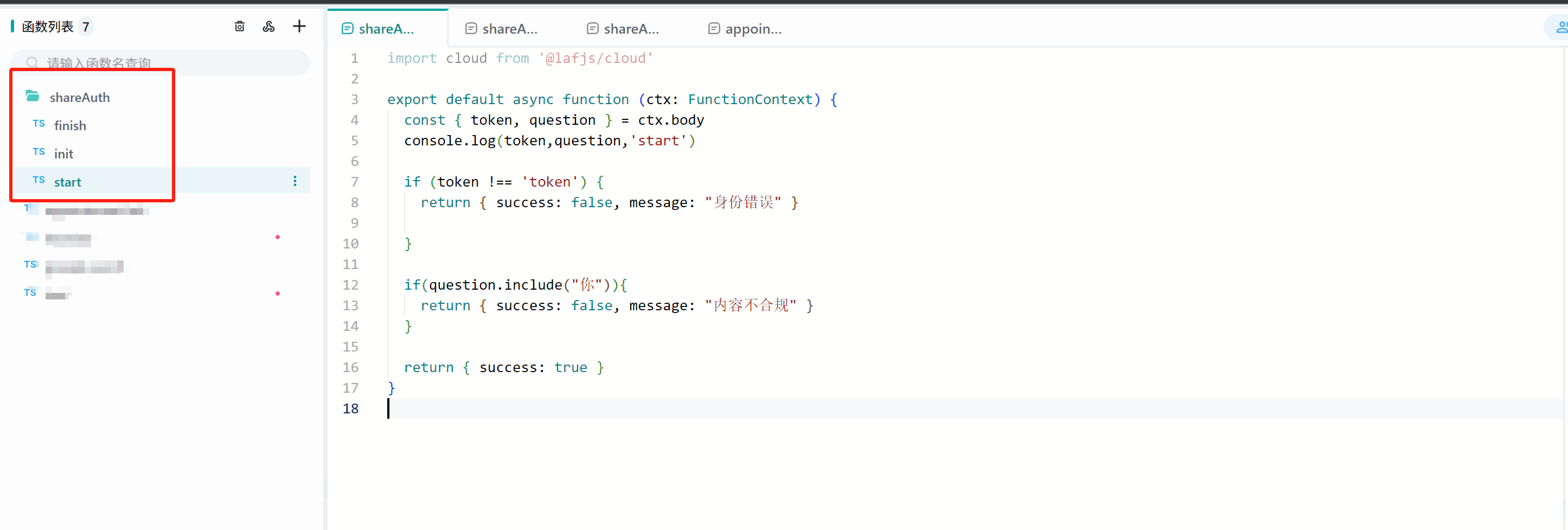
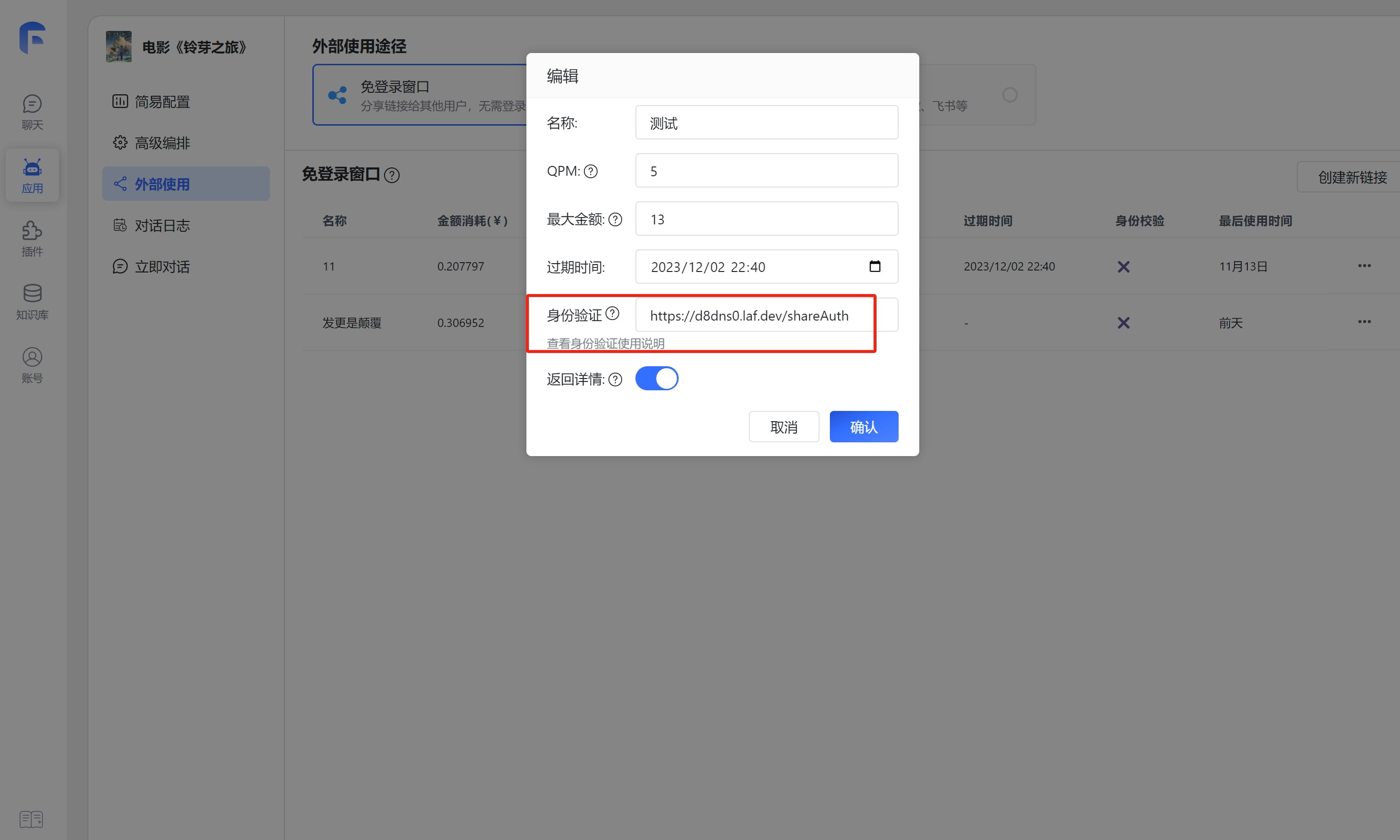
2. 配置校验地址
我们随便复制3个地址中一个接口: https://d8dns0.laf.dev/shareAuth/finish, 去除/shareAuth/finish后填入身份校验:https://d8dns0.laf.dev
3. 修改分享链接参数
源分享链接:https://share.tryfastgpt.ai/chat/share?shareId=64be36376a438af0311e599c
修改后:https://share.tryfastgpt.ai/chat/share?shareId=64be36376a438af0311e599c&authToken=fastgpt
4. 测试效果
- 打开源链接或者
authToken不等于fastgpt的链接会提示身份错误。 - 发送内容中包含你字,会提示内容不合规。
使用场景
这个鉴权方式通常是帮助你直接嵌入分享链接到你的应用中,在你的应用打开分享链接前,应做authToken的拼接后再打开。
除了对接已有系统的用户外,你还可以对接余额功能,通过结果上报接口扣除用户余额,通过对话前校验接口检查用户的余额。