文件输入功能介绍
FastGPT 文件输入功能介绍
从 4.8.9 版本起,FastGPT 支持在简易模式和工作流中,配置用户上传文件、图片功能。下面先简单介绍下如何使用文件输入功能,最后是介绍下文件解析的工作原理。
简易模式中使用
简易模式打开文件上传后,会使用工具调用模式,也就是由模型自行决策,是否需要读取文件内容。
可以找到左侧文件上传的配置项,点击其右侧的开启/关闭按键,即可打开配置弹窗。
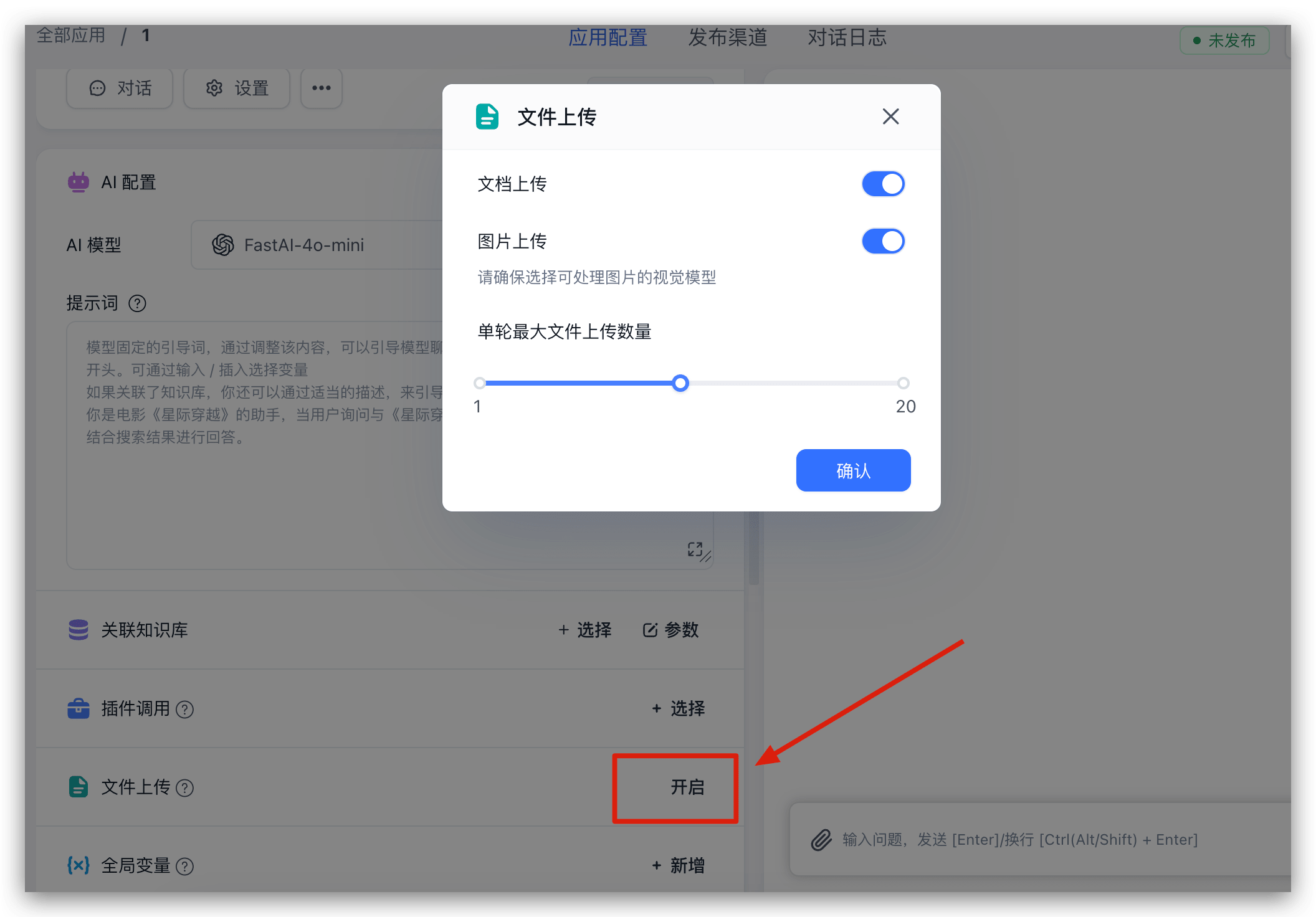
随后,你的调试对话框中,就会出现一个文件选择的 icon,可以点击文件选择 icon,选择你需要上传的文件。
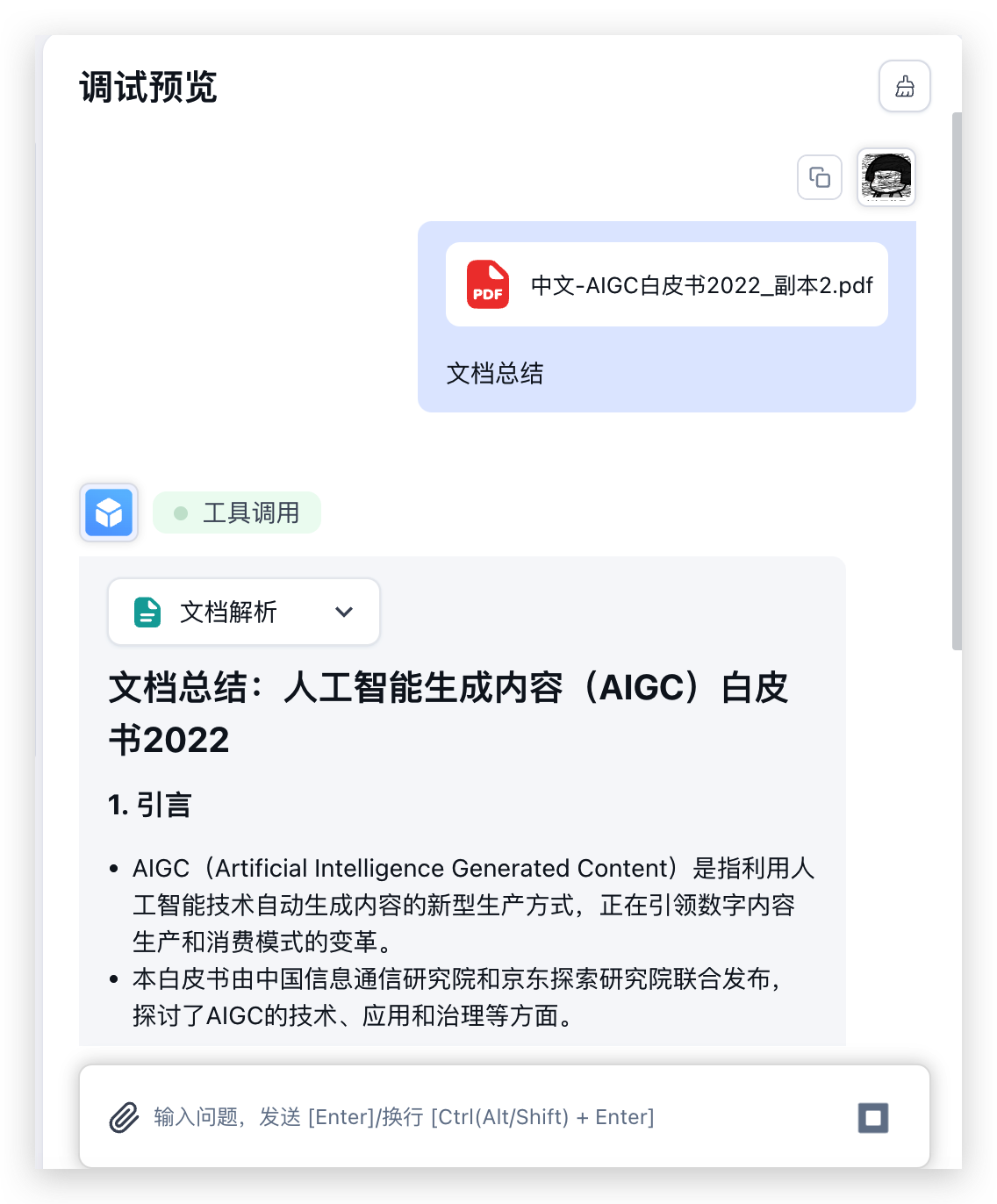
工作模式
从 4.8.13 版本起,简易模式的文件读取将会强制解析文件并放入 system 提示词中,避免连续对话时,模型有时候不会主动调用读取文件的工具。
工作流中使用
工作流中,可以在系统配置中,找到文件输入配置项,点击其右侧的开启/关闭按键,即可打开配置弹窗。
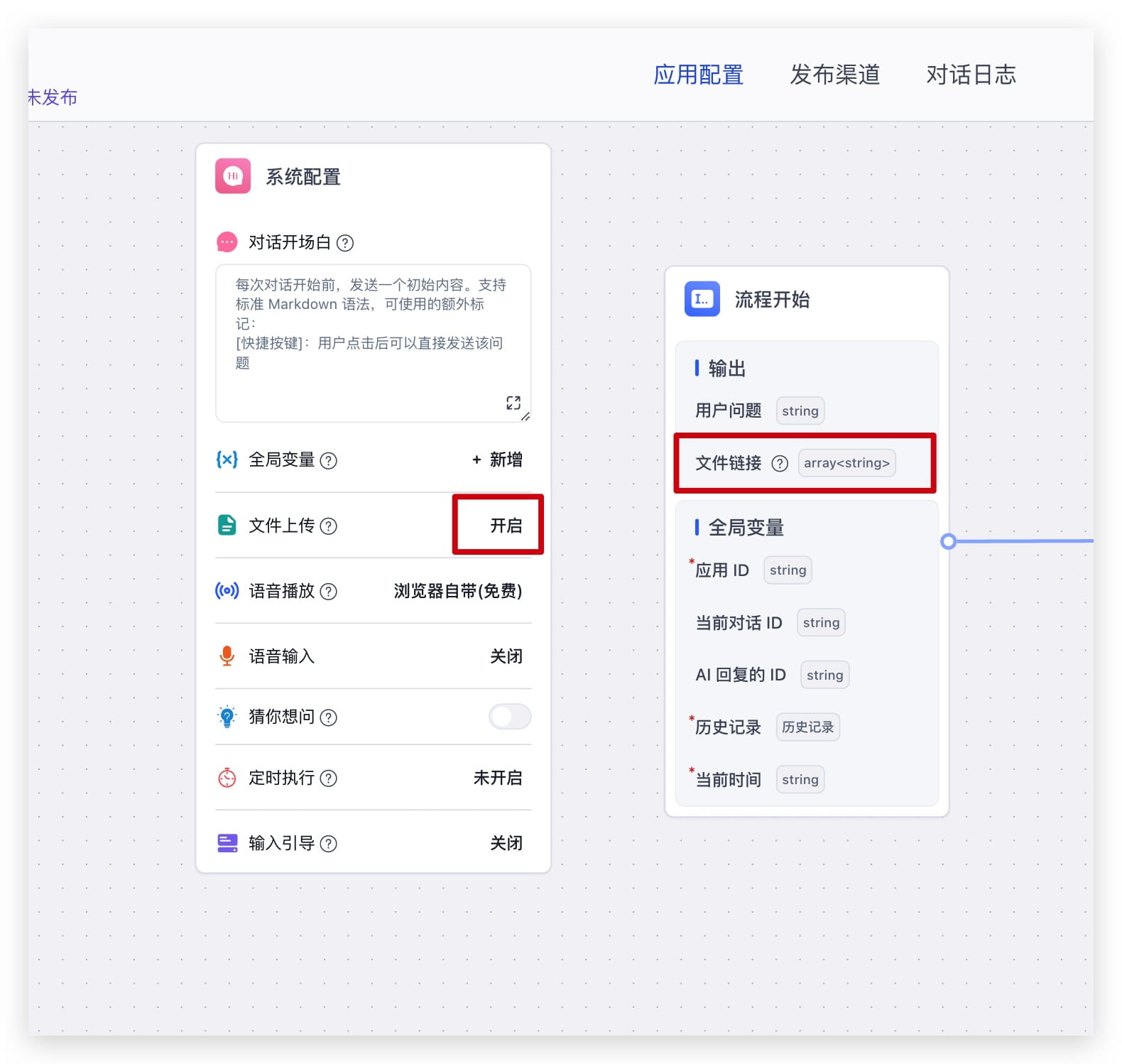
在工作流中,使用文件的方式很多,最简单的就是类似下图中,直接通过工具调用接入文档解析,实现和简易模式一样的效果。
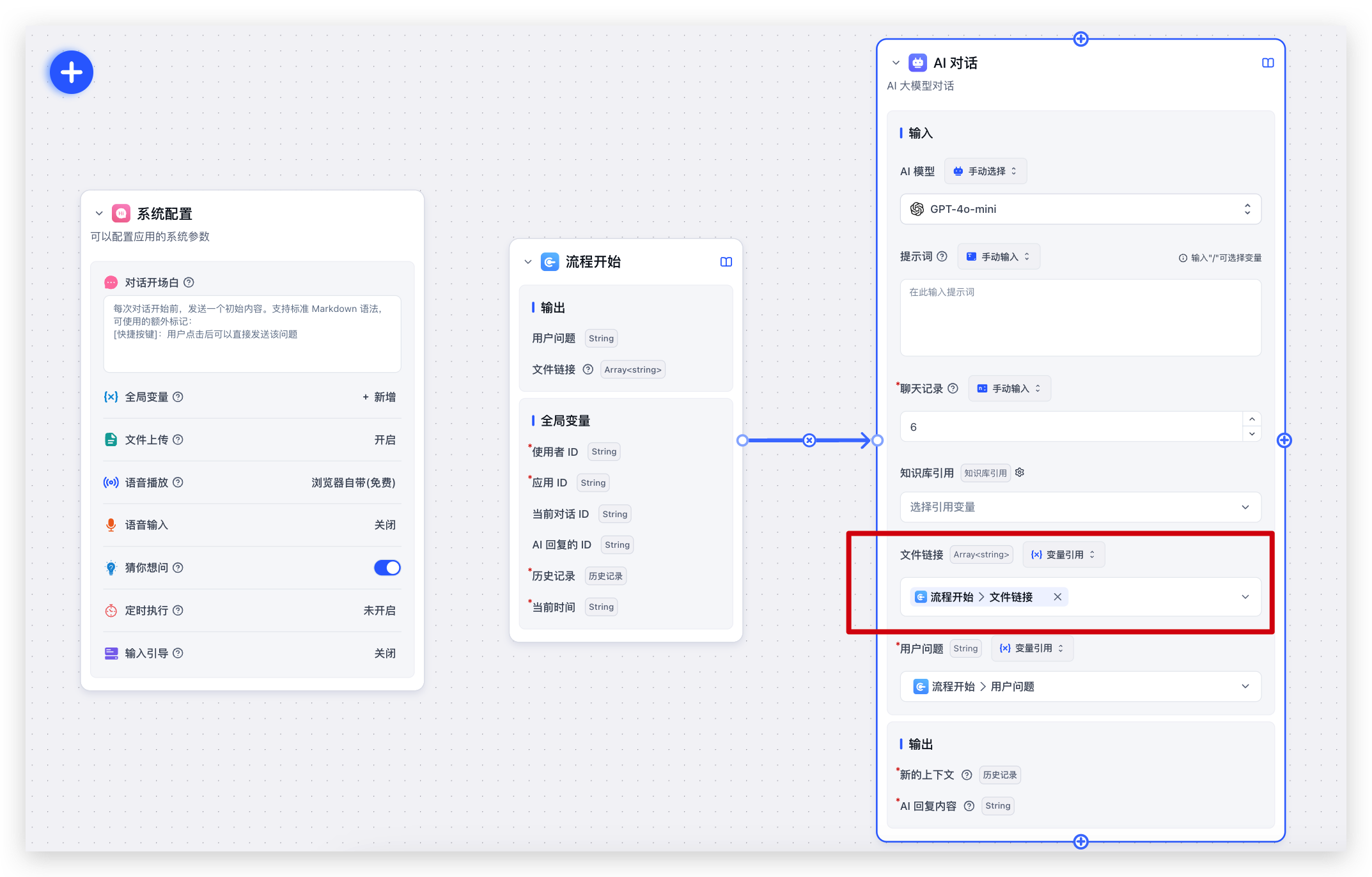 | 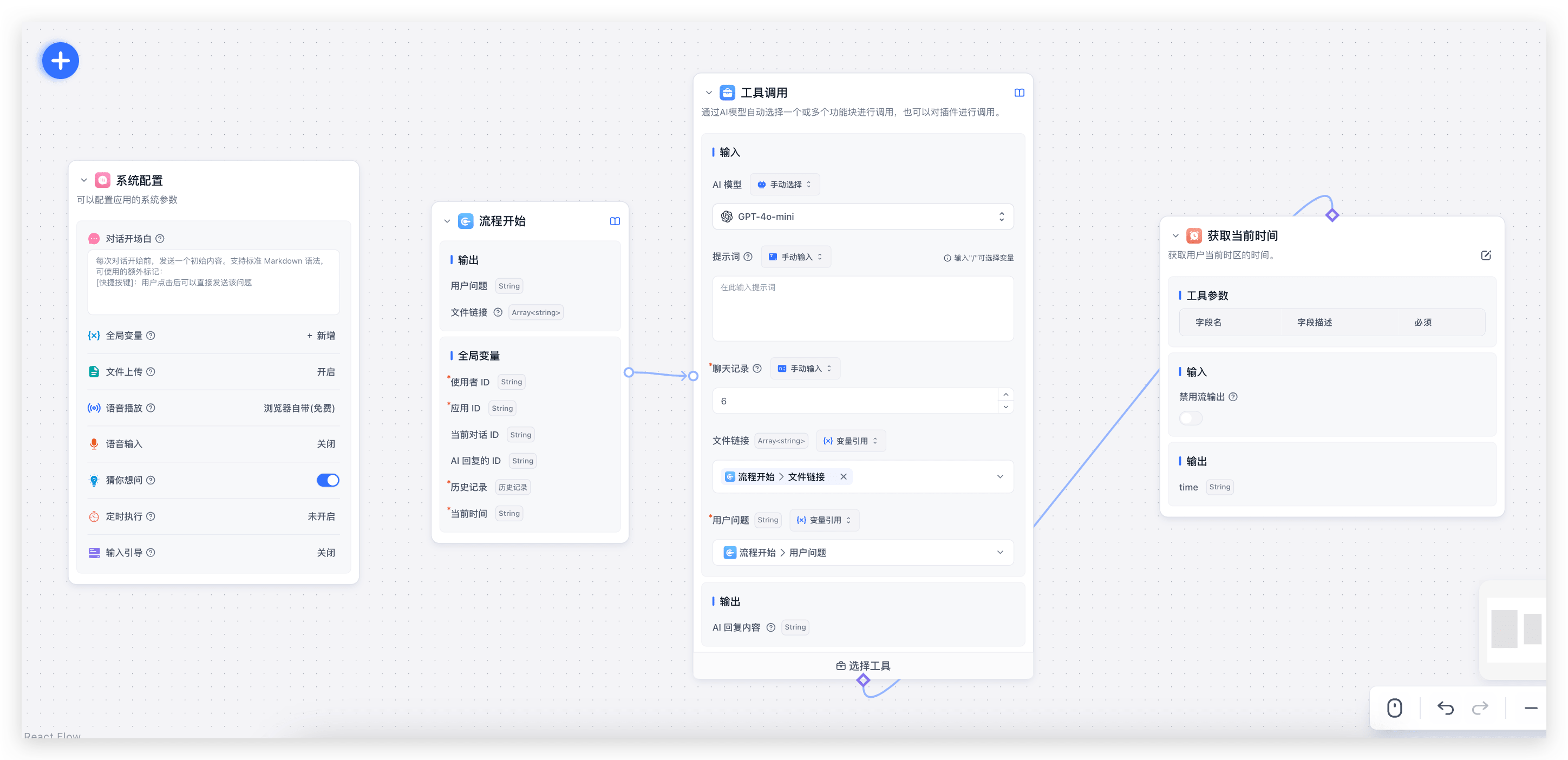 |
当然,你也可以在工作流中,对文档进行内容提取、内容分析等,然后将分析的结果传递给 HTTP 或者其他模块,从而实现文件处理的 SOP。
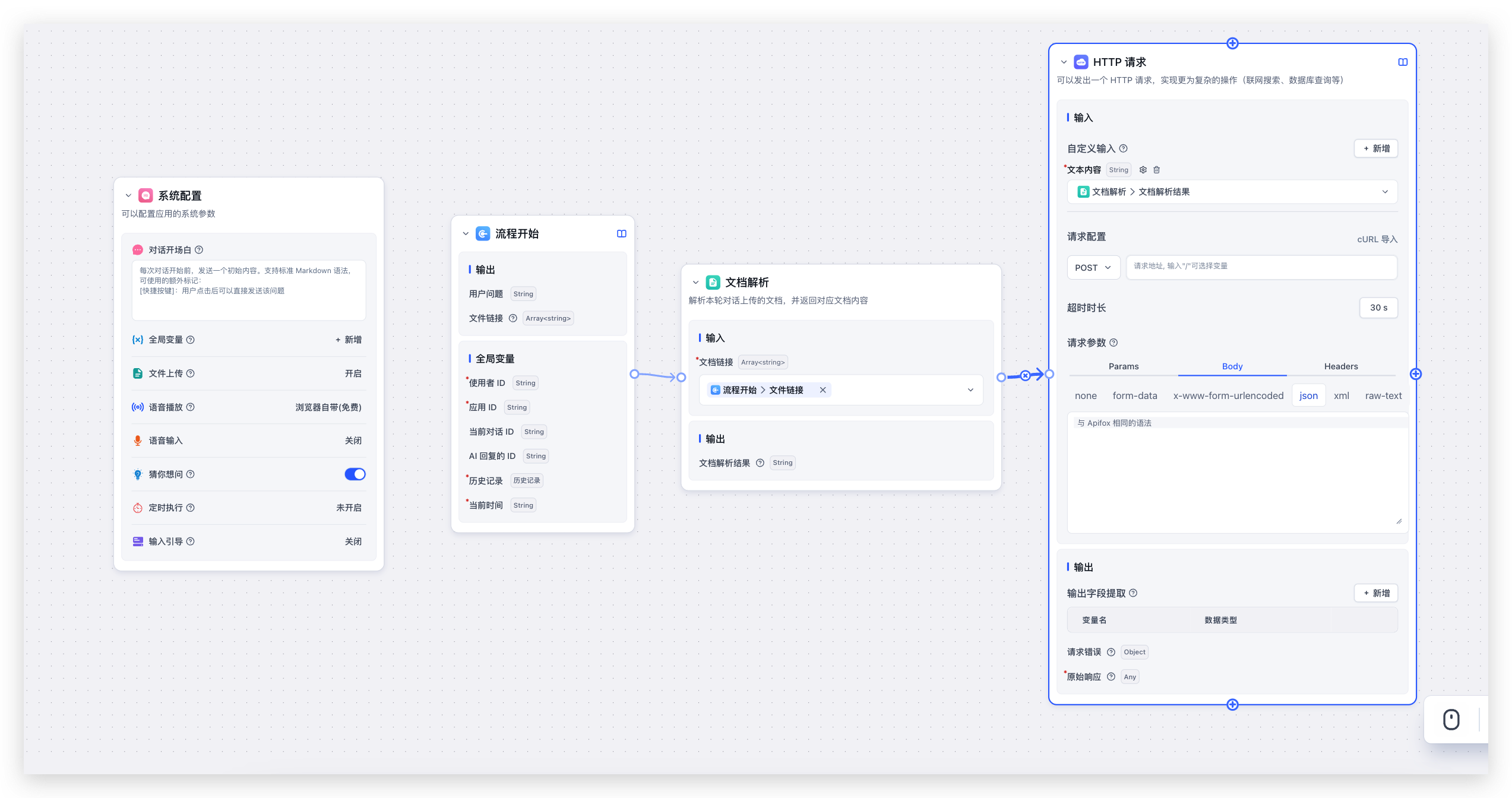
文档解析工作原理
不同于图片识别,LLM 模型目前没有支持直接解析文档的能力,所有的文档“理解”都是通过文档转文字后拼接 prompt 实现。这里通过几个 FAQ 来解释文档解析的工作原理,理解文档解析的原理,可以更好的在工作流中使用文档解析功能。
上传的文件如何存储在数据库中
FastGPT 的对话记录存储结构中,role=user 的消息,value 值会按以下结构存储:
type UserChatItemValueItemType = {
type: 'text' | 'file'
text?: {
content: string;
};
file?: {
type: 'img' | 'doc'
name?: string;
url: string;
};
};
也就是说,上传的图片和文档,都会以 URL 的形式存储在库中,并不会存储解析后的文档内容。
图片如何处理
文档解析节点不会处理图片,图片链接会被过滤,图片识别请直接使用支持图片识别的 LLM 模型。
文档解析节点如何工作
文档解析依赖文档解析节点,这个节点会接收一个array<string>类型的输入,对应的是文件输入的 URL;输出的是一个string,对应的是文档解析后的内容。
- 在文档解析节点中,只会解析
文档类型的 URL,它是通过文件 URL 解析出来的文名件后缀去判断的。如果你同时选择了文档和图片,图片会被忽略。 - 文档解析节点,只会解析本轮工作流接收的文件,不会解析历史记录的文件。
- 多个文档内容如何拼接的
按下列的模板,对多个文件进行拼接,即文件名+文件内容的形式组成一个字符串,不同文档之间通过分隔符:\n******\n 进行分割。
File: ${filename}
<Content>
${content}
</Content>
AI节点中如何使用文档解析
在 AI 节点(AI对话/工具调用)中,新增了一个文档链接的输入,可以直接引用文档的地址,从而实现文档内容的引用。
它接收一个Array<string>类型的输入,最终这些 url 会被解析,并进行提示词拼接,放置在 role=system 的消息中。提示词模板如下:
将 <FilesContent></FilesContent> 中的内容作为本次对话的参考:
<FilesContent>
{{quote}}
</FilesContent>
4.8.13版本起,关于文件上传的更新
由于与 4.8.9 版本有些差异,尽管我们做了向下兼容,避免工作流立即不可用。但是请尽快的按新版本规则进行调整工作流,后续将会去除兼容性代码。
- 简易模式中,将会强制进行文件解析,不再由模型决策是否解析,保证每次都能参考文档。
- 文档解析:不再解析历史记录中的文件。
- 工具调用:支持直接选择文档引用,不需要再挂载文档解析工具。会自动解析历史记录中的文件。
- AI 对话:支持直接选择文档引用,不需要进过文档解析节点。会自动解析历史记录中的文件。
- 插件单独运行:不再支持全局文件;插件输入支持配置文件类型,可以取代全局文件上传。
- 工作流调用插件:不再自动传递工作流上传的文件到插件,需要手动给插件输入指定变量。
- 工作流调用工作流:不再自动传递工作流上传的文件到子工作流,可以手动选择需要传递的文件链接。