英语作文纠错机器人
spellcheck
英语作文纠错机器人
使用 FastGPT 创建一个用于英语作文纠错的机器人,帮助用户检测并纠正语言错误
FastGPT 提供了一种基于 LLM Model 搭建应用的简便方式。
本文通过搭建一个英语作文纠错机器人,介绍一下如何使用 工作流
搭建过程
1. 创建工作流
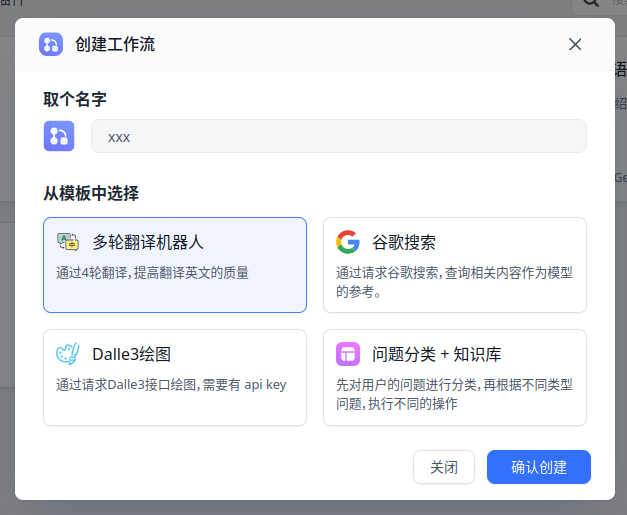
可以从 多轮翻译机器人 开始创建。
多轮翻译机器人是 @米开朗基杨 同学创建的,同样也是一个值得学习的工作流。
2. 获取输入,使用大模型进行分析
我们期望让大模型处理文字,返回一个结构化的数据,由我们自己处理。
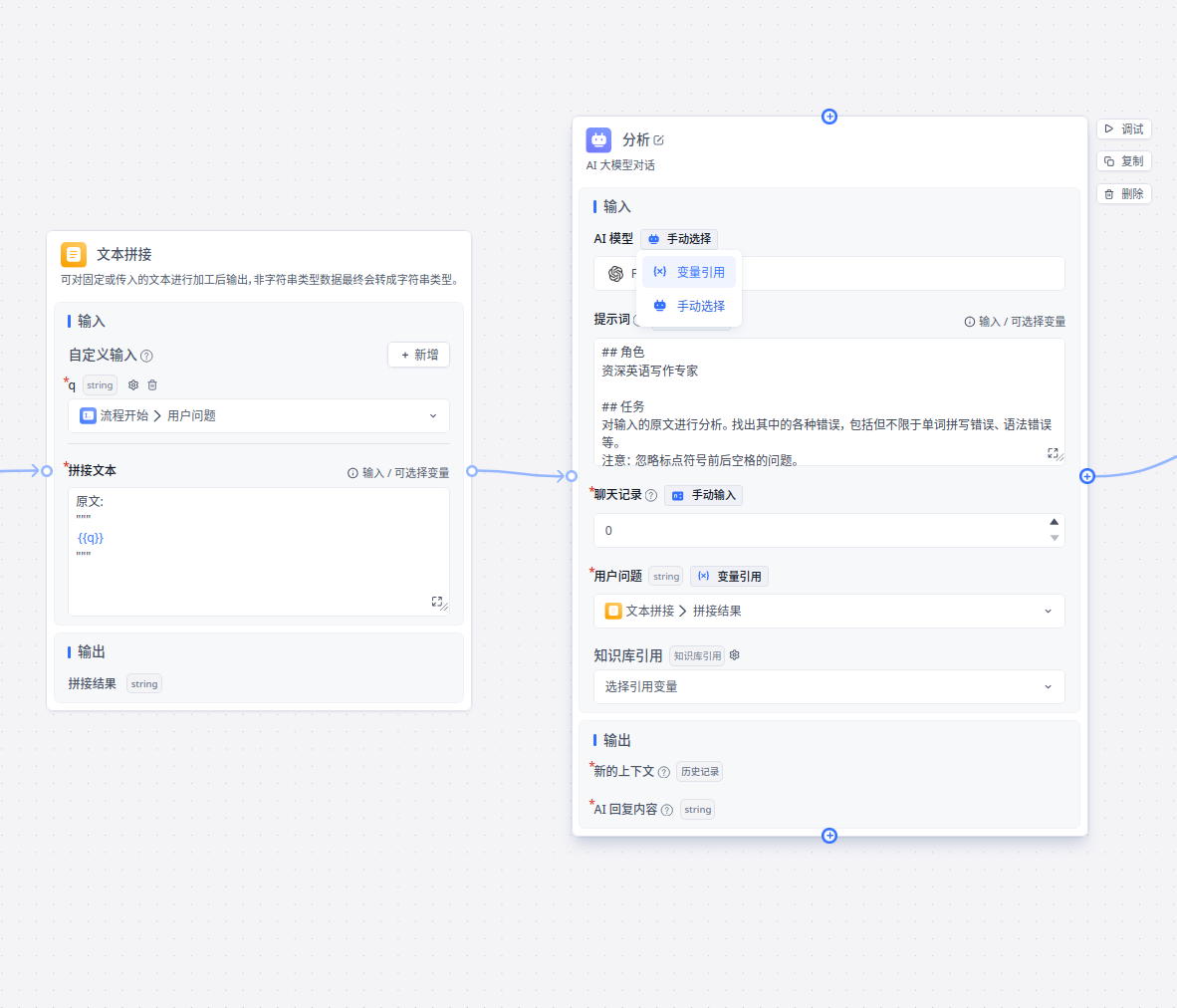
提示词 是最重要的一个参数,这里提供的提示词仅供参考:
## 角色
资深英语写作专家
## 任务
对输入的原文进行分析。 找出其中的各种错误, 包括但不限于单词拼写错误、 语法错误等。
注意: 忽略标点符号前后空格的问题。
注意: 对于存在错误的句子, 提出修改建议是指指出这个句子中的具体部分, 然后提出将这一个部分修改替换为什么。
## 输出格式
不要使用 Markdown 语法, 输入 JSON 格式的内容。
输出的"reason"的内容使用中文。
直接输出一个列表, 其成员为一个相同类型的对象, 定义如下
您正在找回 FastGPT 账号
```
{
“raw”: string; // 表示原文
“reason”: string; // 表示原因
“suggestion”: string; // 修改建议
}
```
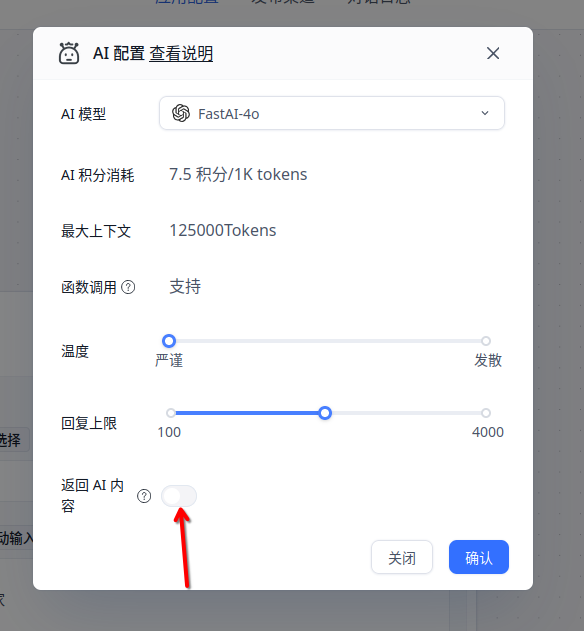
可以在模型选择的窗口中设置禁用 AI 回复。
这样就看不到输出的 json 格式的内容了。
3. 数据处理
上面的大模型输出了一个 json,这里要进行数据处理。数据处理可以使用代码执行组件。
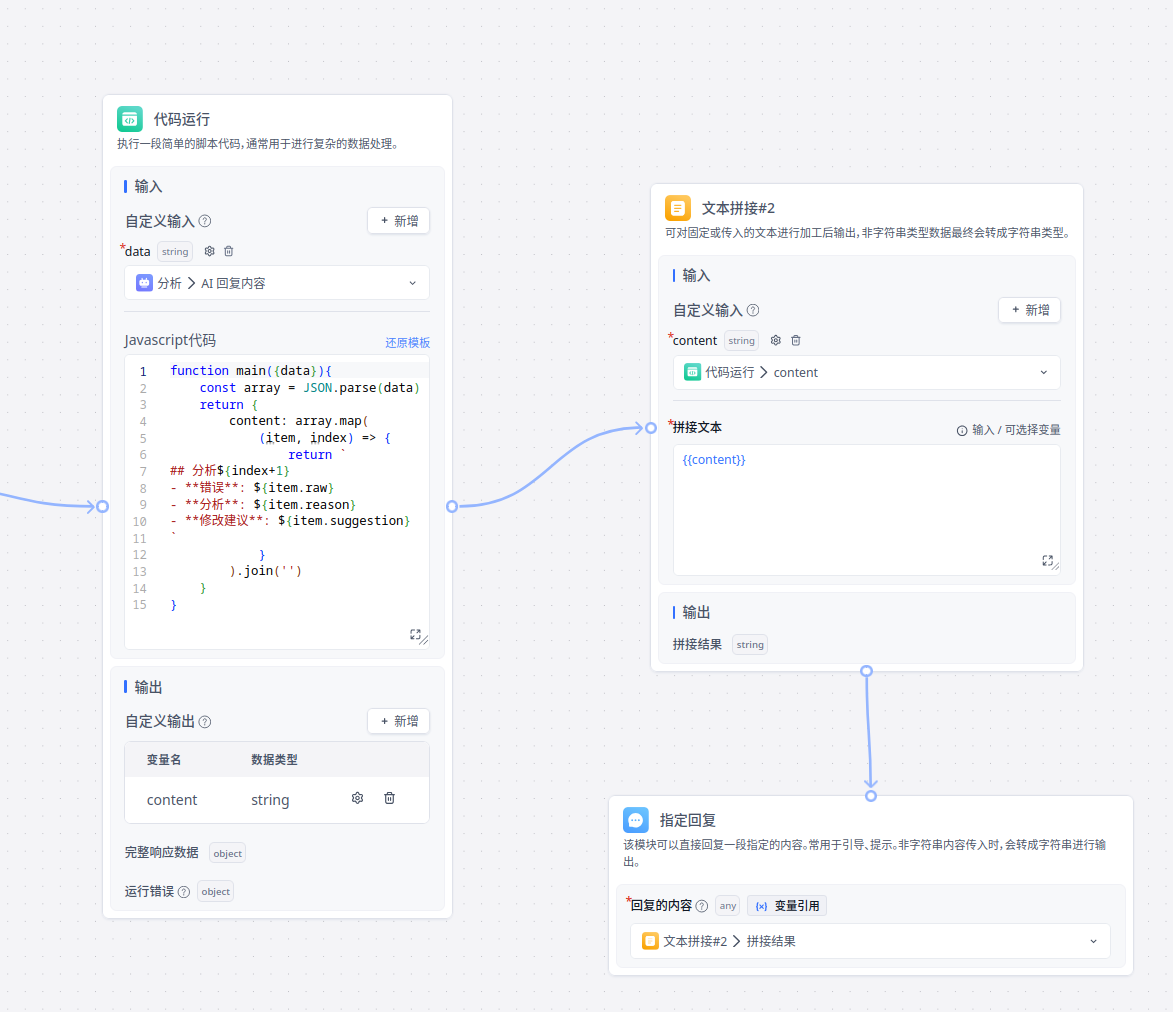
function main({data}){
const array = JSON.parse(data)
return {
content: array.map(
(item, index) => {
return `
## 分析${index+1}
- **错误**: ${item.raw}
- **分析**: ${item.reason}
- **修改建议**: ${item.suggestion}
`
}
).join('')
}
}
上面的代码将 JSON 解析为 Object, 然后拼接成一串 Markdown 语法的字符串。
FastGPT 的指定回复组件可以将 Markdown 解析为 Html 返回。
发布
可以使用发布渠道进行发布。
可以选择通过 URL 访问,或者是直接嵌入你的网页中。